データサイエンスとは?定義やスキルセットについて解説

当記事は「データサイエンスをビジネスに活用したい」「データサイエンスを活用する際の概観を知りたい」といった方を対象に、以下に挙げた項目の説明を通じて、データサイエンスとその活用法への理解を深めていただくことを目的にしています。
- データサイエンスとは
- データサイエンティストのスキルセット
- データサイエンスができること
「データサイエンスができること」では、弊社による実際の分析事例も含めてご紹介します。データサイエンスを活用したいとお考えの方にとって、当記事が次のステップに踏みだす足がかりとなれば幸いです。
執筆者のご紹介
武藤 賢悟(むとう けんご)
東北大学薬学部大学院修了後、大手食品メーカーにて統計解析を含む研究業務および商品開発に従事。その後2021年にDAへ中途入社し、現在までEC事業会社に常駐。ほか、教育事業会社や化粧品会社への常駐経験を経て、現在に至る。DAではサービス開発室に所属し、エキスパート人材として高度な分析手法を用いることで、クライアントのビジネス成果創出に貢献している。
目次
01.|データサイエンスとは
02.|データサイエンティストのスキルセット
03.|データサイエンスができること
04.|おわりに
データサイエンスとは
筆者が調査した限り、「データサイエンス」という学術領域に対して、世界共通の普遍的な定義はないようです。
これはおそらく、一般的にデータサイエンスの領分とされるデータの扱い方や解析技法が、現在進行形で進歩を続けていることと、その活動領域がいくつかの高度な専門分野にまたがっていることから、世間一般が描くデータサイエンス像が理解されづらく流動的であるゆえだろうと思われます。ハーバード公衆衛生大学院で教鞭をとっているHernán教授も、データサイエンスに関する考察の冒頭で次のように述べています。
We argue that a failure to adequately describe the role of subject-matter expert knowledge in data analysis is a source of widespread misunderstandings about data science.
データ分析における専門知識の役割を適切に説明できない原因は、データサイエンスに対する広範な誤解にあると主張したい。 (筆者訳)
– 出典:Miguel A. Hernán, et.al "Data science is science's second chance to get causal inference right: A classification of data science tasks"(2024年11月19日に利用)
この状況をふまえた上で、あえて現在における「データサイエンス」の定義を考えるにあたっては、いくつかの見解を見比べることが有効だろうと思われます。
筆者が調査したなかで最も簡潔な定義は、googleの元チーフデータサイエンティストであるKozyrkov氏による以下のものです。
Data science is the discipline of making data useful.
データサイエンスは、データを便利にする学術分野である。(筆者訳)
–出典:Cassie Kozyrkov"What on earth is data science?"(2024年11月19日に利用)
この定義には個人的に首肯できるものの、いささか抽象的すぎるため、他にもいくつかの定義を確認しました。
データに隠されている実用的な洞察を、専門知識、数学と統計、特殊プログラミング、高度な分析、人工知能(AI)、
機械学習を組み合わせて明らかにすることです。
得られた洞察は、意思決定と戦略計画策定の指針として活用できます。
–出典:IBM「データサイエンスとは?」 (2024年11月19日に利用)
データサイエンスは、ビジネスにとって意味のあるインサイトを抽出するためのデータの研究です。
これは、数学、統計、人工知能、コンピュータエンジニアリングの分野の原則と実践を組み合わせて、
大量のデータを分析する学際的なアプローチです。
この分析は、データサイエンティストが、何が起こったのか、なぜ起こったのか、何が起こるのか、
結果で何ができるのかなどの問題を提起し、答えるのに役立ちます。
–出典:AWS「データサイエンスとは」 (2024年11月19日に利用)
データサイエンティスト(分析人材)とは、高度に情報化された社会において、
日々複雑化及び増大化(ビッグデータ化)するデータを、利用者の利用目的に応じて情報を収集・分析する技術を有し、
ビジネスにおいて実行可能な情報を作ることができる者をいう。
– 出典:一般社団法人データサイエンティスト協会「協会概要」(2024年11月19日に利用)
これらの定義から最小公倍数的な要素を抽出し、筆者はビジネス活用をめざしたデータサイエンスを次のように解釈しました。
- データに対して、さまざまな専門技術を使い、ビジネスの意思決定をたすける「情報」や「洞察」を抽出すること。
また、ビジネスの意思決定はPDCAサイクルやOODAループの一部として説明されるように、おおむね「課題の設定 -> 現状の確認 -> 解釈 -> 意思決定」というフローを経るものと想定されます。この流れにもとづいて考えると、データサイエンスは意思決定に先行する「現状の確認」および「解釈」のステップを科学的なアプローチによって慎重に進める営みとも解釈できそうです。
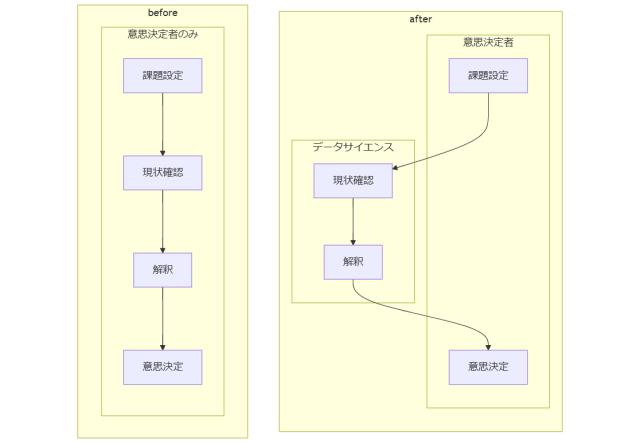
データサイエンティストのスキルセット
では、データサイエンスの実践者たる「データサイエンティスト」は、どのようなスキルセットをもってデータサイエンスを行っていくのでしょうか? 「データサイエンス」に対する共通の定義がない以上、その担い手のスキルセットも同様に共通見解を見出すことは難しいようです。データサイエンティスト協会の目的に
社会のビッグデータ化に伴い重要視されているデータサイエンティスト(分析人材)の育成のため、
その技能(スキル)要件の定義・標準化を推進し、社会に対する普及啓蒙活動を行う。
とあることからも、逆説的にデータサイエンティストのスキルセットが流動的であることが示唆されます。
このような状況を鑑み、当記事では現在のデータサイエンティストがもつ個別具体の技術 (例: Pythonのxxモジュール, yy機械学習, etc..) には言及しません。今後しばらくは普遍的に求められるであろう、要素レベルでのスキルセットについて考えていきたいと思います。これにあたっては、IBMによるデータサイエンティストの記述が参考になりました。
”データサイエンスは学術分野で、データサイエンティストはこの学術分野における実践者であると考えられています。
データサイエンティストは必ずしも、データサイエンスのライフサイクルに伴うすべてのプロセスに直接的な責任
を負うわけではありません。
例えば、データ・パイプラインは通常、データ・エンジニアが処理します。
しかし、データサイエンティストがどのような種類のデータが便利であるか、
あるいは必要であるかについて提案する場合があります。
データサイエンティストは機械学習モデルを構築できる一方、
こうした取り組みを大規模なレベルで拡張するにはプログラムを最適化してより迅速に実行できるようにするための
ソフトウェア・エンジニアリング・スキルがさらに求められます。
そのため、データサイエンティストが機械学習エンジニアと協力して機械学習モデルを拡張するのは珍しいことではありま
せん。”
–出典:IBM「データサイエンスとは?」 (2024年11月19日に利用)
ここから、データサイエンティストはデータサイエンスのすべての行程を単独で行うとは限らず、周辺領域のスペシャリストやアナリストとの協力のもと業務にあたることが一般的だとわかります。
また、データサイエンティストはその軸足をデータの分析に置いているため、特定の調査対象に関するドメイン知識が十分でないことは珍しくありません。したがって、データサイエンティストがその業務を全うするためには、意思決定者や調査対象の実務担当者を通して十分なドメイン知識を得ることも重要な必要条件の一つです。
以上を踏まえ、引き続きIBMのデータサイエンティストの技術要件を確認します。
”つまり、データサイエンティストは次のことができる必要があります。
- 適切な質問をし、ビジネスの問題点を特定するために、ビジネスを十分に知る。
- 統計とコンピューター・サイエンスをビジネス感覚とともにデータ分析に適用する。
- データの準備と抽出のために、データベースとSQL、データ・マイニング、データ統合の手法まで、あらゆるツールと手法を使用する。
- 予測分析と 機械学習モデル、 自然言語処理、 ディープラーニングを含む人工知能(AI)を使用してビッグデータから洞察を抽出します。
- データ処理と計算を自動化するプログラムを作成する。
- あらゆる技術的な理解レベルを持つ意思決定者と利害関係者に対して、結果の意味を明確に伝えるためのストーリーを話し、説明する。
- ビジネスの問題を解決するためにそれらの結果をどのように利用できるか、説明する。
- データ・アナリスト、ビジネス・アナリスト、ITアーキテクト、データ・エンジニア、アプリケーション開発者など、他のデータサイエンス・チームのメンバーと協力する。”
–出典:IBM「データサイエンスとは?」 (2024年11月19日に利用)
十分に整理されており蛇足であることは否めませんが、あえてさらに要約するならば、
- 意思決定者や調査対象の実務者を介して、ドメイン知識や要件を把握する。
- データサイエンスに関する各分野のスペシャリストとの協力体制を築く。
- 課題に対して適切な分析計画や手法を選択し実施する。
- 得られた示唆を意思決定者に理解してもらえるように見せ方を工夫する。
以上がデータサイエンティストが果たすべき要件だといえそうです。
データサイエンスができること
データサイエンスが特定のビジネス領域に留まらず、学術的研究や政策決定にも応用可能であることについては、当記事ではことさらに言及しません。
では、応用先によらずデータサイエンスが果たせる要素はどのようなものなのでしょうか。Hernán教授はデータサイエンスの果たす役割を考えるにあたって、そのアウトプットを「意味」や「洞察」とするのは曖昧すぎると述べ、より具体的な要素として次のような分類を提唱しています。
The scientific contributions of data science can be organized into three classes of tasks: description, prediction, and counterfactual prediction
データサイエンスによる科学的な貢献は「記述」「予測」「反実仮想」の3つに分類できる。(筆者訳)
– 出典:Miguel A. Hernán, et.al "Data science is science's second chance to get causal inference right: A classification of data science tasks"(2024年11月19日に利用)
当記事でもこの分類にならい、それぞれの概要と事例を説明します。
記述 (description)
概要
データを使って、あるできごとを定量的に要約することを指します。要約した値の可視化もこれに含まれます。
技術
平均値や割合計算などの簡単な計算から、次元削減や教師なし学習などに代表される技術に至るまでの広汎な技術が用いられます。
可視化にあたっては、データサイエンティストに親しまれているPythonやRのモジュールや、TableauやPowerBIなどに代表されるBIツールを活用するケースが一般的です。
例
- デジタル庁の関連政策のダッシュボード
- ビジネスロジックから導き出された顧客のセグメンテーション
- 利便性・視認性の高いダッシュボードの作成 (弊社事例)
都内の歓楽街と商店街の振興にむけた施策に携わった弊社社員の事例を紹介します。地域の商店からのヒアリングで収集した安全性や店舗区分に関するデータを整理し、地図上で情報を視認できるダッシュボードを構築しました。
図1
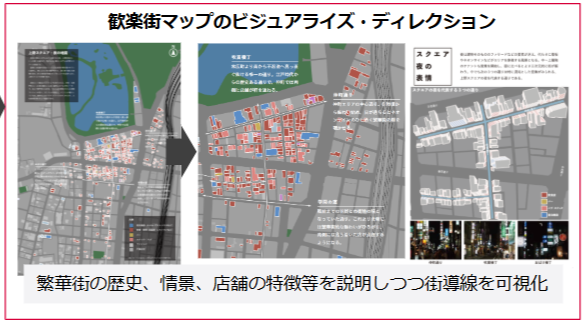
図1出典:弊社事例集(2024年11月19日に利用)
予測 (prediction)
概要
あるデータから、他のデータの値を予測することを指します。予測する値は、元の値との関係性がうたがわれる値や、元の値の将来にわたる値などが該当します。
技術
相関係数やリスク比などの簡単な計算から、統計モデリング・機械学習・ニューラルネットワークなどを活用するケースなど、記述と同様に広汎な技術が用いられます。
例
- 気象予報
- 売上の時系列予測 (社内事例)
あるECサイトについて、顧客ごとの購買行動を考慮した売上予想モデルを作成したことがあります。
商材の特性上、顧客は1年周期である程度きまった範囲での支出を行うことが想定される市場でした。そのため、顧客ごとの前年までの売上データを用いて、年間の購買確率と購買時の金額期待値を推定しました。
反実仮想の予測 (counterfactual prediction)
概要
ビジネス上の意思決定においては、"ある意思決定の結果が目標に対してどのような効果をもたらすか" –言い換えれば、意思決定を行った場合の目標は、行わなかった場合と比べてどの程度変わるか- に関する示唆が重要であるケースが珍しくありません。
このような課題が設定された場合、「記述」や「予測」の結果は直接的な解答たりえないことがあります。 たとえば、売上を精度よく予測することに成功したとしても、これは「売上を最大化させるための広告出稿配分はどのようなものか?」といった意思決定にはなんら答えを提供してくれません。
"反実仮想"とは、実際にあるイベントが起きた現実に対し「もしイベントがなかったら?」というifの世界を指します。反実仮想下での目標値の様子を推定することができれば、現実の目標値との差から、イベントが原因でもたらされた変化を定量的に評価することができます。
技術
反実仮想を正確に推定するためには、主に統計学分野の十分な知識が必要とされるだけでなく、「関心のあるできごとがどのような力学で動いているのか」に関する実務者の十分な知見や仮説も必要不可欠です。なぜならば、反実仮想の予測とは、乱暴にいえば「興味のある値の変化にかかわるすべての値をシミュレーションすることで、ある特定のイベントの有無による差を調べる」ものであるためです。必然的に、記述や予測とくらべて達成難易度の高いタスクといえます。
なお、すでに得られた過去のデータから得られる反実仮想への示唆は非常に限定的であり、より精緻な予測をしたい場合には試験を行うことが推奨されます。ウェブマーケティングの分野では、ある施策をセッションごとにランダムに割り当てることで施策の効果を推定する「ABテスト」が実施されるケースが散見されますが、これも試験の一形態です。
ただし、ABテストから関心のある反実仮想を正確に予想するためには、本当にランダムな割り付けがされているか、判断したいことに対して適切な統計手法の選択と解釈ができているか、評価結果による受益者と評価者が同一でデータを剽窃するモチベーションが働かないかなど、いくつかの専門的な見地から慎重な計画と実施が求められます。
例
- 健康診断を受診することの、大腸がんでの死亡率に与える効果の推定
- ある施策の効果を評価できる指標への影響に対するABテスト
- 還元施策接触者の、ある期間の売上増分を推定 (事例)
ある還元施策が実施されたあとにその効果検証を計画することになり、施策による売上への効果を推定したことがあります。
このようなケースでは、施策に接触した顧客の売上と接触していない顧客の売上を単純比較しがちですが、施策に接触する人としない人では平時での売上や施策接触後の反応が同じだとは考えにくく、計算結果にこれらのギャップが混じってしまいます。
ここで知りたいことは「実際に施策に接触した顧客の、施策による売上への作用」です。このような状況では、顧客ごとの施策接触率を何らかの方法で導き出し、これに応じてデータの重みを変えることで「施策に接触した可能性の高い顧客のなかで、施策に接触した人と接触しなかった人の差を推定する」アプローチが一般的です。この事例でも、内部に機械学習のアルゴリズムを組み込みつつ、上記のようなアプローチで施策効果の推定を実施しました。
おわりに
ここまで、「データサイエンス」「データサイエンティスト」とはどのようなものなのか、複数の見解を参照しつつ考えてきました。
また、さまざまな領域での応用ができるデータサイエンスについて、その普遍的な役割についてもHernán教授の分類を交えて紹介しました。
周辺技術のめぐるましい進歩やセンセーショナルな活用事例が喧伝されやすい環境にあって、その輪郭が見えにくいデータサイエンスですが、この記事が地に足のついたデータサイエンスの活用法を考える一助になることを願います。
また、お持ちの個別具体な課題に対してデータサイエンスがどのように活用できるか、データサイエンスによる意思決定を推進するためにはどうすればいいかといったご相談も弊社では承っております。この記事をご覧になって気になることがございましたら、ぜひご気軽にご連絡くださいませ。
\ データ活用についてのご相談はメンバーズデータアドベンチャーまで /
▶こちらも要チェック
データアドベンチャーのサービスご紹介
参考資料
- IBM, "データサイエンスとは", (accessed 2024-11-19)
- 一般社団法人データサイエンティスト協会, "協会概要", (accessed 2024-11-19)
- Amazon Web Services, Inc, (2024), "データサイエンスとは", (accessed 2024-11-19)
- Miguel A. Hernán, et.al, (2019), "Data science is science's second chance to get causal inference right: A classification of data science tasks"
- Cassie Kozyrkov, (2018), "What on earth is data science?" (accessed 2024-11-19)
- デジタル庁, "政策ダッシュボード一覧", (accessed 2024-11-19)




