2024年7月23日(火)に開催される、 Marketing Native編集部主催『Marketing Native Fes 2024 Summer』にカンパニー社長の白井が登壇します。
登壇概要
Marketing Native Fes 2024 Summer
登壇セッション:データから事業上の成果を生むためにデータ分析の前にやるべきこと
セッション概要:BtoBビジネスにおいても、データやAIの活用が進む中、多くの企業がデータサイエンティスト育成に取り組み、分析ツールに投資しています。
一方で、組織が上手く立ち上がらず、データ分析の成果もまだ見えてないという問題に直面している企業も多いのではないでしょうか。
本セミナーでは、企業がデータを「役立つ」レベルまで活用するために重要な「分析する前」に焦点を当て、組織のつくり方や業務フローについて解説いたします。
データを組織内で効率的に活用する方法を摸索している方に必聴の内容をお届けします。
日時:2024年7月23日(火)14:30~14:50
場所:オンライン
参加費:無料
詳細:https://marketingnative.jp/mnfes03
登壇者紹介
白井 恵里(しらい えり)

株式会社メンバーズ 執行役員
兼 メンバーズデータアドベンチャーカンパニー社長
東京大学を卒業後、株式会社メンバーズへ入社。
大手企業のオウンドメディア運用、UXデザイン手法での制作や、デジタル広告の企画運用に従事したのち、2018年11月に社内公募にてメンバーズの子会社(現、社内カンパニー)社長として株式会社メンバーズデータアドベンチャーを立ち上げ。
データアナリスト、データサイエンティスト、データエンジニアなどデータ領域のプロフェッショナルの常駐により企業のデータ活用を支援し、顧客ビジネス成果に貢献するサービスを提供。
2020年10月から株式会社メンバーズ執行役員兼務。現在カンパニーに所属するデータ分析のプロフェッショナルは約150名。
2024年、一般社団法人Generative AI Japan立ち上げに伴い、理事就任。
X @EriShirai
当サイトにて『メディア』ページをリリースしました。
データ活用に役立つ記事をご覧いただけますので、ぜひご利用ください。
こんにちは。データアドベンチャーの北島です。
今回は、データ活用を「これからはじめよう」または「はじめているが自分たちのやっていることが正しいのか不安を感じている・・」そんなみなさまへお伝えしたい内容です。
執筆者のご紹介
北島史徒
株式会社メンバーズ メンバーズデータアドベンチャー サービス開発室 所属
戦略プランナー
データ活用におけるお客様の課題に対して高付加価値のサービスを提供する「エキスパートサービス」の開発や、実際にお客様へ課題のヒアリング~提案業務を行っています。
経歴:2019年 株式会社メンバーズ入社。顧客専任のデジタルマーケティング運用支援チームのマネージャーとして顧客のデジタルトランスフォーメーション(以下DX)やカスタマーサクセスの推進を支援。2023年からデータアドベンチャーのサービス開発室へジョインし、データをキーに顧客のDX、カスタマーサクセスの推進をサービス開発という立場から後方支援しています。
目次
01.| データ活用、何からはじめる?
02.| とりあえず社内ではじめてみた、でも不安・・
03.| データ活用に必要なプロセスとは?
04.| データ活用に必要な環境とは?
05.| データ有識者をお客様のすぐそばに
データ活用、何からはじめる?
①そもそもデータ活用とは?
企業が業務で発生する情報をデータとして収集・蓄積したり、または分析することで、社内の生産性向上や売上向上などをビジネスに役立てることを目指す取り組みです。
②データ活用のメリットは?
データは1つ1つに意味があり重要な資産ですが、そのデータをどう読み解いてビジネスに役立てるかがビジネス成果を目指す上で重要になってきます。データに関する理解度や読み解くスキル、データによる意思決定を定着させる社内の組織的な文化の醸成が大変重要になってきます。
③お客様のよくあるお困りごととは?
ふだん私たちがお客様との対話の中で、よくお聞きする内容です。
データ活用がこれからのお客様のお悩み

※当社サービス資料より引用
経営層などから中期経営計画でDXの推進といった戦略が掲げられ、取り組む方針も漠然と抽象度の高い状態で与えられるケースが一般的です。
戦略や方針が落ちてきても次の具体的なアクションについて「何をどのように進めたらいいのかわからない・・」そのような声をよくお聞きしてきました。
とりあえず社内ではじめてみた、でも不安・・
ふだん私たちがお客様との対話の中で、よくお聞きする内容です。
データ活用を進めているお客様のお悩み
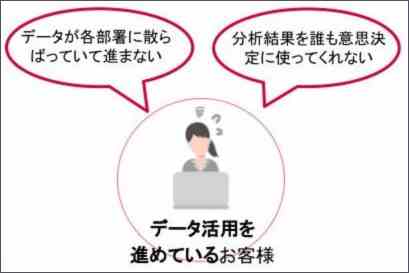
※当社サービス資料より引用
これらの背景としては、社内人材のデータに関する知見・ノウハウ不足が挙げられることが多いです。
- データ活用を推進したいが、データに詳しい特化人材がいない
- 本業と兼務し片手間でデータ分析をしている
- データ人材を育成しよう!といっても、そのノウハウが社内に無い
データ活用に必要なプロセスとは?
データアドベンチャーでは、データ活用を大きく3つのフェーズ、8つのステップに分類することで、お客様がどのプロセスでお困りごとがあるのかをお伺いしています。
データ活用のプロセス
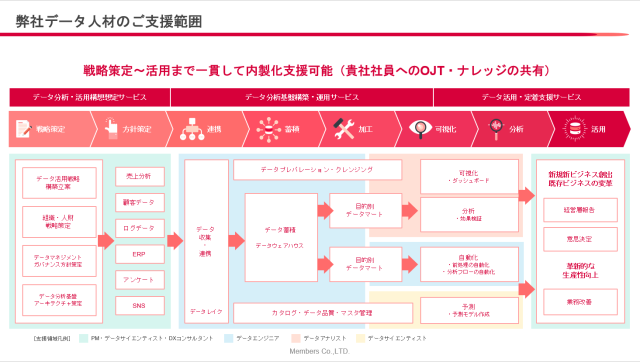
※当社サービス資料より引用
3つのフェーズ
- データ分析・活用構想:データ活用の戦略や目的を策定するフェーズ
- データ分析基盤構築・運用:データ分析環境を作り、導入するフェーズ
- データ活用・定着:データによる意思決定サイクルを回し定着させるフェーズ
8つのステップ
- 戦略策定
- 方針策定
- 連携
- 蓄積
- 加工
- 可視化
- 分析
- 運用
データ活用に必要な環境とは?
データアドベンチャーではデータ活用に必要な環境を、「データ分析基盤」と呼んでいます。
この基盤は以下の役割を担っています。
①データ分析基盤の役割
- データを収集する
- データを蓄積する
- データを加工する
- データを可視化する
- データを分析する
ひと昔前は、データをCSVに吐き出して、エクセルなどで手作業で集計や分析を行う方法がありました。昨今は扱うデータ量が多くなり、SaaSと呼ばれるデータ分析ツールを導入するお客様が増えてきた印象です。
②SaaS導入のメリット
SaaSとは?
Software as a Serviceの略称で「サービスとしてのソフトウェア」を言います。ことデータ活用の世界では「データの収集と分析を支援するクラウドサービス」を主に一般的に利用することが多いです。
SaaSのメリット
データ分析基盤には、SaaS(クラウドサービス)とオンプレミス(on-premises)環境の2つがあります。
オンプレミスは、サーバーやソフトウェアなどの情報システムを企業の設備内に現物を設置し運用することを指しますが、企業専用に環境をオーダーメイドするため、イニシャルコストが大きく導入期間も長くなる傾向にあります。
※データ量が莫大に多く、SaaSの機能ではカバーできない場合はオンプレミスを選択する必要が出てきます。
これに対しSaaSはクラウドサービスで用意された機能を予算に応じてお好みに選ぶことができます。サービス利用は従量課金制のためイニシャルコストを抑え小さく早く始められるのがオンプレミスと比較した場合のメリットです。
また、SaaSのサービスは必要な機能を必要な時に追加することができるため、環境面でもお客様のビジネスの変化に応じて柔軟に対応することが比較的容易です。
SaaSの分類と代表例
データ分析基盤の役割において、SaaSの担う範囲を整理すると、以下のように大きく3つの分類にわけることができます。
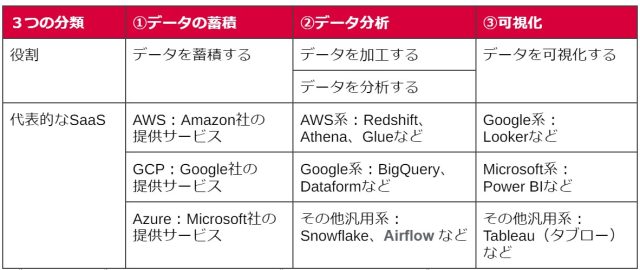
※データの収集はデータ環境によってSaaSの導入が必要な場合と不要な場合があるため本編では割愛します
※データ分析においてデータの前処理・加工を施すETL(Extract Transform Load)と呼ばれるプロセスが入りますが、本編ではETLの話題は割愛します
SaaS導入でありがちなこと
「①データの蓄積」や「②データ分析」のツール選定と導入においては専門的な知識が必要なため、お客様側で気軽に導入することが難しい傾向にあります。
一方で「③可視化」は、BI(ビジネスインテリジェンス)ツールがよく用いられます。可視化の表現はグラフや図、表など様々です。これらの情報をまとめてダッシュボードに情報を構築することで素早く社内で意思決定できるようにします。
BIツールはGUI(グラフィックインターフェース)で直感的なマウス操作で設定が可能なため、専門知識のないユーザー自身で分析やレポート作成ができるのが特長の1つです。
そのためこれからデータ活用をしていこうとするお客様にあたっては、まずは「可視化」を優先しBIツールを初めに導入される企業が多い傾向にあります。
そして、手探りながらも可視化をしてみたデータ活用を推進しているメンバーに新たな壁が立ち塞がります。
たとえば、
- その可視化したデータが正しい情報なのか?といったお悩み
- そもそも可視化によってどのような示唆や行動を社内に促したいのか?が不明確
そのようなメンバーの漠然とした心配が徐々に蓄積し、「可視化しても社員は見るだけで終わり、あるいは誰も見てくれない」といった問題がいよいよ表面化し、何とか対策を講じないといけない・・・といったことが往々にして起こります。
このようにせっかくコストをかけてSaaSのツールを導入したものの、使いこなせない、使われない状態では非常にもったいない話ですよね。
データ有識者をお客様のすぐそばに
データ活用を絵に描いた餅にしないために
ツールが先か?戦略が先か?という議論は尽きない話題ですが、DXをいち早く推進しなければならない時代背景もあるので、現実は小さく導入できるところからする、走りながら考える、といった企業が多いのではないでしょうか。
通常よくある話では、データ活用の戦略ではコンサル事業ベンダーが担当し、施策実行になると派遣・施策実行ベンダーが担当することで、この両者の役割の違いからGAPが生まれ、戦略で描いた施策が思うように進まずに絵に描いた餅になる、といったことを耳にすることがよくあります。
データアドベンチャーの強みは「伴走型支援」
データアドベンチャーではこのようなベンダーの分断を無くし、上流から下流工程までお客様のデータ活用の「伴走型支援」に強みを持っています。

※当社サービス資料より引用
大きな特長として、
- お客様のオフィスに常駐しコミュニケーションを密にする
- お客様のビジネス理解を深め「あたかも社員」のようにご支援する
- お客様のビジネスフェーズやニーズにあわせて最適な人材を提供する
- データ業務のプロセスや仕組みを平準化し、お客様の内製化をご支援する
といったことが挙げられます。
指示待ちの受け身型ではなく、カスタマーサクセス思考の強い自走自立型のクリエイターをご提供することをモットーとしています。
データアドベンチャーのサービスご紹介
データアドベンチャーではお客様のデータ活用フェーズに応じたサービスメニューや人材をご用意しております。

※当社サービス資料より引用

※当社サービス資料より引用
詳細をまとめた資料をダウンロード頂けますのでぜひご活用ください。
またデータ活用に関する困りごとやご相談がございましたら、お気軽にお問い合わせください。
\ データ活用についてのご相談はメンバーズデータアドベンチャーまで /
\ 相談する前に資料を見たいという方はこちら /
本記事では以下の3点について実際の事例を元にお伝えします。
- データ活用は事業全体での取り組みであること
- データ活用はビジネスの実情に合わせつつ成長・変革を先導していくこと
- データチームはその中心で活躍し周囲を巻き込むこと
執筆者のご紹介
吉川寛
所属:株式会社メンバーズ メンバーズデータアドベンチャーカンパニー サービス開発室 室長
企業のデータ活用を強力に進めるために不可欠なスキルやジョブを定義しそれらを提供するためのサービスの開発を担当
データサイエンティストとして顧客企業に常駐し、現在はWebサイト訪問時の購入予測モデルの構築や、サービスの需要予測モデルのチューニングを担当
経歴
人事コンサルタント、事業会社での経営企画を経て2020年2月にメンバーズ入社
顧客企業にデータサイエンティストとして常駐しデータチームの立上げとグロース、施策効果検証や需要予測分析、社内データ活用レベルの向上を狙った勉強会を開催してきました。2023年から現職。
目次
01.| 組織編制において留意すべき前提条件
02.| 今回のポイント
03.| 黎明期
04.| 成長期
05.| 成熟期
06.|まとめ
組織編制において留意すべき前提条件
企業には多くの部署があり人がおり、そしてその相互の関係性から組織が構築されています。そのためデータ活用・DXを進めたい時に他社事例をマネして組織を作ってもうまく行かないことがしばしばあります。経営陣はどの程度の投資を決めているのか、経営陣のリテラシーはどの程度なのかといった意思決定者の状況も違えば、データ活用で実際に施策を動かすマーケティングチームやセールスチームのモチベーションも違います。またデータ活用のための環境や既に利用しているツールも違います。最初に取り組むべきはこれらの診断です。そのためこの記事では「どのような組織を作ったのか」ではなく「どのように組織を作ったのか」にフォーカスします。
今回のポイント
今回ご紹介する事例の企業様は次のような状態でした。データはサービスを動かすためのサーバ上にのみ存在し、ビジネスチームがデータを利用する際はシステム開発部に依頼していました。システム開発部はサービスの保守運用業務があるためデータ抽出などは後回しになりやすく、ビジネスチームは社内報告に必要な最低限のデータ利用に閉じていました。またそれを解決するための知見をもった社員がいなかったため状況改善は成されませんでした。そのためデータ活用の意欲は低くいわゆる「勘と経験」に頼った施策展開が行われていました。
これを問題視した経営陣の判断で弊社にお声がけをいただきました。経営陣は投資意欲は高いが何をしていいかわからない状態であったため、どのようなプロセスであるべき姿に辿り着くかを提示する必要があり、なおかつ現実にビジネスの変化に合わせて柔軟な対応を求められました。
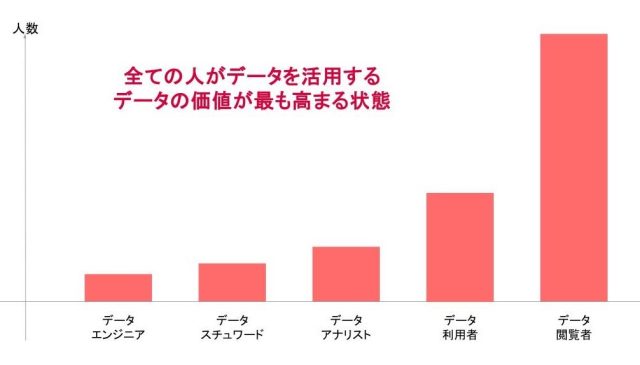
また最終的にはデータユーザーを企業内全員にする、いわゆるデータの民主化を目指します。データはそれだけでは価値がなく使われて初めて価値が生まれます。そのために多くの人がデータを使えるようにすることを目指しました。しかし既存業務で多忙な中、学習することが難しいためビジネスチームがデータを利用するコストを極限まで下げることも必要でした。
そこで今回はまずビジネスチームのデータ需要を喚起しユースケースを回収、それに見合った最低限のデータ分析基盤を構築し、実際の活用度合いやビジネス変化に合わせてデータ分析基盤を成長させ、その後にデータ利用コストを下げていくという大まかな方針をたてました。
※当社セミナー資料より引用
黎明期
今回は初期に「ビジネスチームのデータ需要を喚起しユースケースを回収」という目標があるためこれを実現する活動を行いました。企業に新しくできた部署は周囲から見ると何をする役割なのかわからないことがしばしばです。そして当然ですがそのような部署に情報は回ってきません。
そこで立ち上げ当初はデータチームのできることを提示しその存在価値と利用方法を周知することに努めました。最低限の環境とデータ利用による需要予測モデルの作成、そこから得られる示唆と施策への提言やデータ集計の依頼喚起のためのヒアリングや依頼対応、相談に対応しました。このフェーズではとにかくデータの可視化が重要です。そもそもどのようなデータがあるのか社内に周知されていませんし、どのようにデータを集計したり読めばいいのかわからないという状態であるため、可視化されたデータはそれだけで強力なコミュニケーションツールとなります。複雑な需要予測であっても最終的なわかりやすい可視化を表示し説明する、売上集計では興味のありそうなセグメント別の結果をビジネスチームがインタラクティブに操作できるような可視化を行います。
こうした取り組みの結果、データチームの存在価値が周囲に認められ、企業内の様々なデータ需要が集まる部署に変貌させることができました。
このように黎明期はとにかく周囲を巻き込み主体的に推進できるアナリストやサイエンティストの活躍が重要です。いかに事業に資する分析やデータ活用のパターンを収集できるかによってその後のデータチームの在り方が変わってきます。
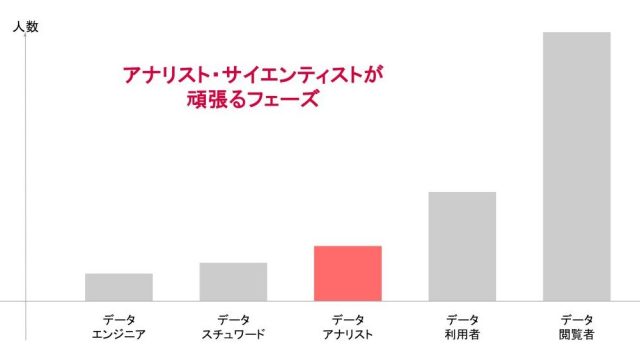
※当社セミナー資料より引用
成長期
続く成長期では徐々にリソース不足が顕在化します。効率化されていないデータ分析基盤と存在価値が増えたからこそ起きる依頼過多が要因です。これらは顕在化したと同時に直ちに取り掛かることをお勧めします。というのもデータ分析基盤の要件定義や人員確保はそれなりに工数がかかり、なおかつ不可逆性がそれなりに高いため慎重な計画が必要になるからです。データユーザーの顕在ニーズを迅速に叶えられその先の要望を先回りして提案できるデータアナリストやデータ分析基盤の設計や運用ができるデータエンジニアを優先的にアサインします。
ユースケースが収集・蓄積され理想的なデータ分析基盤を構築したくなりますが、このフェーズでは必要最小限に留めることをお勧めします。理想的なデータ分析基盤を作るには収集・蓄積されたユースケースを抽象化しそれを実現する要件定義を行う必要がありますが、この段階ではそれを完全に近い状態で行う情報もリソースも無いことが普通です。またビジネスの変化もあるため成長・拡張を前提とした必要最小限のデータ分析基盤を構築します。クラウドサービスを使うことでこの実現が容易となりますので活用しましょう。
加えて引き続き経営層との信頼関係を構築するため事業におけるデータ分析・データ活用の有効性や展望を発信することも忘れないようにします。ビジネスチームに対しては受け身の姿勢から攻めに転じます。具体的には分析上有用なデータが生成できるように施策実施や収集データの再設計などを提案します。ABテストはその代表例です。施策設計段階からデータ分析の設計をすることでよりビジネスの意思決定に利用しやすい、尚且つ有用なデータとなることを提案していきます。
同時にデータチームへの要望を受け取れる環境も作っておきます。データ活用が進むと徐々にビジネスチームから他社事例などを参考に「このような分析はできないのか?」と言った要望が得られるようになります。これらはユースケースとして大変貴重なので会議体を設けるなどして情報収集できるように仕組みを作っておくと良いでしょう。
このような「健全な領空侵犯」が実を結ぶと、ビジネスチーム側にも成功体験が蓄積され社内でのデータ利活用が一気に加速します。
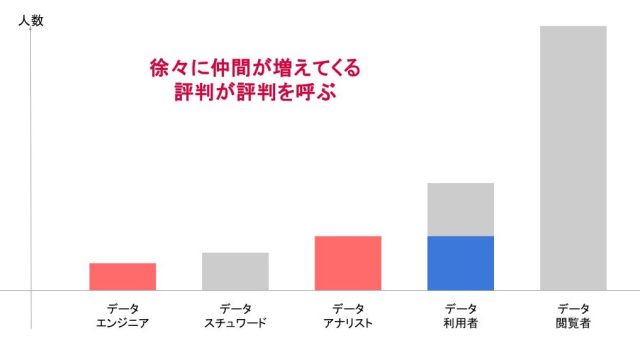
※当社セミナー資料より引用
成熟期
最後の成熟期では、データ活用に関するトラブルを未然に防ぐため、守りを固めていきます。よくある例としては売上の定義です。消費税は含むのか、事業ポートフォリオ上のどの範囲の集計なのかなど事業によって様々な定義がありチームやその時々によって必要なデータが異なります。このようなデータ品質への要求が高まっていくと人力ではリソース上対応不可能になるため、データの要件定義を再精査して統一して管理することで品質を高めていくデータマネジメントが必要となります。
これまでアサインしてきたデータアナリストやデータエンジニア、データサイエンティストに加えデータマネジメント(データ活用全体を統括管理)を担うデータスチュワードを追加する。メンバーが整えば、属人化していたデータ分析の工程をマニュアル化することで品質を高めたり、可視化したデータを一覧にまとめたダッシュボードを構築して視認性を高めたり、といったデータを正確に迅速に取り扱う環境が構築できます。
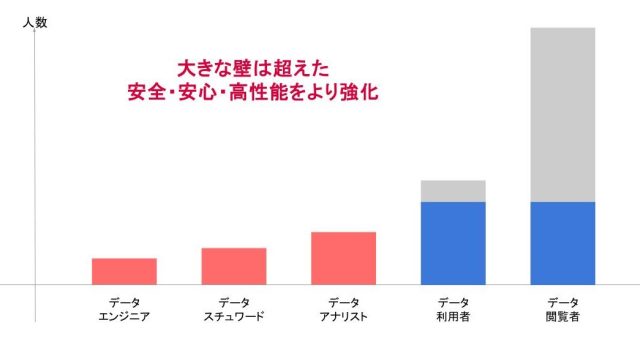
※当社セミナー資料より引用
まとめ
このようにデータ活用の各領域の専任化をビジネスの成長に合わせて必要最低限のコストとその時々で必要十分なデータ活用環境を用意することで、事業のデータ活用を進めることができます。あまりに大きな計画はスタート時点でビジネスチームが理解しにくい状態になりますし、無計画ではデータチームの疲弊が顕著になってしまいます。このバランスは事業によって異なるため、一般的に必要だと言われているデータ活用の要素をどのようなステップでどの程度導入していくか、拡張性をどの程度持たせるかを決定していく必要があります。また必要な人材が都合の良いタイミングで採用できるとは限らないので専門人材の外部調達やツールの導入も視野に入れておくと良いでしょう。
また事業でデータ活用を進めるためには上記の通りデータチームからの働きかけが非常に重要です、データ活用の知識以上にそういった周囲を巻き込み変革していく姿勢が必要なので社内でそのような動きができる人材をデータチームにアサインする方法もあります。その場合もやはり実働部隊が手薄になりやすいので専門人材の外部調達を視野に入れておくと良いでしょう。
\ データ活用についてのご相談はメンバーズデータアドベンチャーまで /
\ 相談する前に資料を見たいという方はこちら /
この記事では、クラウドデータプラットフォームの理解促進のため以下の点についてお伝えします。
- クラウドデータプラットフォームとは何か?
- クラウドデータプラットフォームのメリットについて
- 導入の際に気を付けるべき点や導入後に躓きやすい点
クラウドデータプラットフォームのメリットをお伝えするのはもちろん、導入時に気を付けるべき点・考えるべき点をお伝えします。
執筆者のご紹介
小野琢也
所属:株式会社メンバーズ メンバーズデータアドベンチャーカンパニーアナリスト事業部
現在の担当業務:私の現在の職務といたしましては、ホールディングス会社において各事業会社のデータのAWSクラウドデータプラットフォームへの一元化を行っています。
各社の持つデータをAWSに連携し、データの収集から分析・可視化を行える環境作りを行っています。
経歴:小売り事業の需要予測、Webマーケティングのデータ分析など、データ界隈の業務を行ってきました。
現在は、深層学習分野の学習を行っております。
目次
01.| クラウドデータプラットフォームとは?
02.| データプラットフォームのメリット
03.| 導入の際に気を付けるべき点
04.| 導入後に躓きやすい点
05.| まとめ
クラウドデータプラットフォームとは?
クラウドデータプラットフォームとは、簡単に言ってしまうとクラウド上に配置されたデータセンターのことです。
オンラインベースでデータの保存・管理・分析を行うことができ、異なる組織間でも瞬時にデータの共有を行うことができます。
セキュリティ性も高く、ユーザー毎のアクセス管理やセキュリティイベントの監視を行っています。
もちろん、すでにオンプレミスで用意しているデータ基盤からの連携を行う事もできます。
代表的なサービスとしては、AmazonのAWS、MicrosoftのAzure、Google Cloud Platform(GCP)、Snowflakeなどが有名です。
データプラットフォームのメリット
そのようなデータプラットフォームですが、導入する事のメリットとしてはどのようなものがあるのでしょうか?
大きく分けると以下の2つがあります。
- データを一元化して管理できる
- データの収集~分析までを一貫して行える
まずデータを一元化して管理できるメリットですが、これは私のようにホールディングス会社であったり、部署毎に別のシステムを導入している場合ですと非常に恩恵が大きいです。
各種データを見るのにそれぞれのシステムにアクセスする煩雑さが無くなるのはもちろん、データの整合性と一貫性を保つことができ、データ品質の向上に繋がります。
また、非常に大きいメリットとしてセキュリティの強化を行うことができます。
データを一元管理する事で、アクセスの制御や監査ログの管理が容易になり、セキュリティインシデント対策に非常に効果的です。
細かい点としては、各企業毎にセキュリティポリシーが設けられていると思いますが、それらを遵守しやすくなるといったメリットもあります。
続いてデータの収集~分析までを一貫して行えるメリットについてです。
やはり大きなポイントとしては効率化です。
データの収集から分析までを一つの環境でシームレスに行えるのは非常に効率的です。
私の場合ですと、AWSのS3にデータを貯め、Redshiftで分析に適した形にし、SageMakerで分析を行っています。
このように効率化を図る事もできますし、セキュリティ面から見ても安心です。
もし、データの集積と分析の環境が違う場合ですと、データの持ち出し時にセキュリティインシデントの危険性が高まるのは想像に難くないでしょう。
導入の際に気を付けるべき点
上記のようなメリットのあるクラウドデータプラットフォームですが、導入の際に気を付けておくべきことが3点ほどあります。
- プラットフォームを導入する目的をデータの一元化だけで終わらせない
- データ量や使用用途に合わせてツールは選ぶべき
- ツール導入後のフローや役割分担は事前に決めておく
まず、クラウドデータプラットフォーム導入の目的をデータの一元化としがちですが、本来はその先にあるビジネス価値の最大化を目指すべきです。
データの一元化は重要ですが、それを最終目的とせず、データの一元化によって得られるインサイトや分析結果をもとにビジネス成果に繋げる事が重要です。
また、データ量や使用用途に合わせてツールは選ぶべきです。
小規模なデータ処理にはシンプルさとコスト効率を優先してツールを選ぶべきですが、大規模なデータを扱う場合や、リアルタイム分析が必要な場合などは、ある程度の予算・運用コストを考え、高性能でスケーラブルなプラットフォームが必要になります。
最後に、ツール導入後のフローや役割分担は事前に決めておく事が重要です。
導入したは良いけど基盤構築がうまくいかず分析出来ない、という状況は極力避けたいです。
そのためにも、事前に各種フローや役割分担を明確にしておく事が求められます。
最低限、データの管理者・分析担当者・セキュリティ責任者などの役割を明確にし、業務プロセスやデータの流れを書面化して残しておくことが重要です。
特にデータの流れに関しては後回しにしがちですが、導入時からしっかりと把握する事が大事です。後からデータの流れを把握しようとしても、工数が余計掛かってしまいますし、セキュリティインシデントに繋がる恐れもあります。
必ず書面化し、共有できるようにしておきましょう。
導入後に躓きやすい点
ビジネス課題解決のために導入したクラウドデータプラットフォームですが、導入してから躓いてしまうという事が多いのも事実です。
特に良くあるのが以下の2点です。
- データ量が想定よりも多い
- データの管理は出来るようになったが次に何をしたら良いのか分からない
まず想定よりもデータ量が多い点ですが、特に今まで複数のシステムで管理していたデータを一本化した事により、想定よりもデータ量が多くなってしまうという事があります。
データが複数箇所に散らばってしまっていたため、全容の把握が困難であった事が理由です。
データ量が多くなってしまった結果、パフォーマンスの低下やコスト増に繋がってしまう事もありえます。
こういったことを起こさない為にも、導入前に正確にデータ量を見積もる事が大切です。
また、データ量が増大する事を見越してスケーラブルなソリューションを選択する事も重要です。
もし、それでもデータ量が増大してしまった場合は、データの優先順位を明確にし、不要データの削除やアーカイブ、最適化を行う等といった対策が求められます。
また、データの管理は出来るようになったが次に何をしたら良いのか分からないという事も多いです。
本来解決したいはずのビジネス課題に対して明確なKPIを設定せず、導入自体が目的となってしまうと、この様な事態に陥ってしまいます。
この様なことにならないためにも、大事な事は目標を具体的な指標として定義できているかどうかです。そして、その指標に対して定期的に進捗をモニタリングできる体制を構築することです。
そうする事により、現状分析を行う事ができ、インサイトを得る事ができます。次にそのインサイトに基づき、アクションプランを策定し、PDCAサイクルを回しながら改善を続ける事が重要です。
このように、明確な指標設定が成功への鍵となります。
まとめ
クラウドデータプラットフォームの導入は、データの一元管理をする事ができ、データの収集から分析までを一つの環境で行う事が出来るようになります。それにより、業務の効率化や、セキュリティインシデント対策に非常に効果的です。
しかし、成功には重要なポイントがあります。まず、データの一元化だけを目標とするのではなく、ビジネス価値の創出を見据える事が大切です。
また、データ量や使用用途に応じたツール選定や導入後のフロー、役割分担などを明確にする事も大切です。
明確なビジネス目標と戦略を持つことで、クラウドデータプラットフォームの導入効果を最大限に引き出す事が可能です。
\ データ活用についてのご相談はメンバーズデータアドベンチャーまで /
\ 相談する前に資料を見たいという方はこちら /
この記事ではデータ活用の一つであるデータ分析について、データ分析をするとわかること・データ分析の進め方・具体的な手法の一例をお伝えします。データを何かに使えないか、分析したいけどあまりイメージがわかないような方の参考にしていただけると嬉しいです。
執筆者のご紹介
加藤洋介
所属:株式会社メンバーズ メンバーズデータアドベンチャーカンパニー アナリスト事業部 データアナリスト
常駐による顧客企業のデータ分析支援を行いWebサービスやアプリのユーザー・PVの向上のための意思決定に貢献し、現在はデータマネジメントやダッシュボードの学習中。
経歴
中古自動車のオークション運営会社、健康保険組合の運営支援会社を経て2021年8月にメンバーズ入社
顧客企業にデータ分析者として常駐し要因分析・効果検証による効果的なコンテンツ制作の意思決定の支援を実施。ただ分析するのではなく、課題や分析の目的を整理して、意思決定を支援するデータ分析をしてきました。
目次
01.| データ活用とデータ分析
02.| データ分析をするとわかること
現状把握
効果検証
顧客ニーズの把握
03.| データ分析の進め方
課題を設定する
その課題に対してどのような意思決定をするかを想定しておく
何がわかると意思決定できそうかを考える
分析設計を考える
分析をする
分析結果をまとめる
レポートを作成する
意思決定者に報告をしてフィードバックをもらう
04.| 具体的な分析手法
施策の効果検証
テキストアナリティクス
機械学習による意思決定支援
アンケート分析
05.|まとめ
データ活用とデータ分析
近年、デジタルデータを中心に多くのデータが取得可能になりました。そのため、ビジネスや日常生活においてデータ活用の機会が飛躍的に増え、データ活用が身近になっていると思います。ビジネスにおけるデータ活用ではレコメンドシステム・業務自動化と効率化・意思決定支援のためのデータ分析、日常生活でも天気予報やゴールデンウイークの高速道路渋滞予測、またスマートウォッチによる脈拍の異常検知など、データ活用の恩恵が浸透しています。
このようにデータ活用の用途は多くありますが、ビジネスにおいて最も重要な活用方法の一つは、意思決定支援のためのデータ分析です。データ分析とは、収集されたデータを整理・加工をして、統計学や機械学習を用いて規則性・傾向・違い・相関関係を明らかにし、因果関係を推定することで、意思決定に役立つ知識を提供することです。例えば、市場動向の把握、顧客ニーズの理解、商品開発、マーケティング戦略の立案、リスク管理などに役立ち、様々な意思決定を支援します。
データ分析は、これまでわからなかった新しい知見や興味深い発見も重要ですが、それだけではビジネス課題の解決には不十分です。 データ分析は、意思決定の判断の1つにデータ分析の結果が活用され、ビジネスにおける課題が解決されることが重要です。以前はデータ分析を活用せずに課題を解決してきたことも多いと思います。しかし、近年では複雑な問題も増えています。 例えば、 顧客ニーズの多様化です。顧客のライフスタイルや価値観が多様化し、画一的なマーケティング戦略ではなく、顧客一人ひとりに最適化された商品やサービスを提供する必要性が高まっています。また、気候変動や資源枯渇などの環境問題は企業にとってリスクであり、持続可能な社会の実現に向けて環境に配慮したサービスが求められています。こうした状況下では、データ分析を用いて、より迅速かつ効果的に課題を解決することが必要となります。データ分析は、ビジネス課題の解決と意思決定の質向上に不可欠なツールです。 適切な活用によって、企業の競争力強化に大きく貢献することができます。
データ分析をするとわかること
データ分析をすることでわかることはたくさんあります。今回は現状把握・効果検証・顧客ニーズの把握の3つをご紹介します。
現状把握
- 顧客の属性や行動パターン
年齢、性別、地域、購買回数や購入商品の種類などの購入履歴、Webサイトやアプリの閲覧履歴など、顧客に関する様々なデータを分析することで、顧客像を明らかにすることができます。顧客像を把握することで、より効果的なマーケティング施策を立案することができます。 - 商品・サービスの売れ行き
商品ごとの売れ行き、利益率、在庫状況などを分析することで、人気商品や不人気商品を特定することができます。また、季節や天候、イベントなどの影響も分析することができます。これらの分析結果を踏まえて、商品開発や販促活動に活かすことができます。 - Webサイトのアクセス状況
アクセス数、PV数、平均滞在時間、離脱率などを分析することで、Webサイトの利用状況を把握することができます。また、どのページが人気なのか、どこでユーザーが離脱しているのかなどを分析することができます。これらの分析結果を踏まえて、Webサイトの改善に活かすことができます。 - コールセンターの利用状況
コール件数、平均通話時間、解決率などを分析することで、コールセンターの利用状況を把握することができます。また、顧客からの問い合わせ内容を分析することで、顧客満足度や製品・サービスの課題を特定することができます。これらの分析結果を踏まえて、コールセンターの運営効率化や顧客満足度向上に活かすことができます。
特に現状把握では、関係者間の齟齬をなくすために、用語の定義と共通認識の醸成が不可欠です。例えば、アクセス数やページビュー数においては、対象となるURLと対象外となるURLを明確に定義し、関係者全員が共通認識を持つことで、データ分析の信頼性と整合性を高めることができます。具体的には、〇〇ページを除外する、△△ページのみを対象とするなど、具体的な基準を設けることが重要です。
施策の効果検証
施策の効果検証をすることで、施策が当初の目的を達成できたかどうか、どの程度達成できたのか、達成できていない場合はその原因が何かを明らかにすることにつながります。効果検証を実施するメリットとして、効果的な施策立案や経営資源をより効果的に配分することができます。
効果検証に求められるもっとも重要な性質の1つは再現性です。施策の効果検証をした結果、このような効果があると結論付けても、実際に実行した際に同じような効果が再現されなければビジネス課題の解決と意思決定の質向上に貢献することはできません。再現性のある効果検証を行うためには適切な比較をすることが重要です。
顧客ニーズの把握
- アンケートの分析
アンケートをすることで、顧客の要望や意見を把握することができます。アンケートではWebやはがき、電話などの方法があります。アンケートを実施することで、「なぜこの顧客層は購入しないのか」といった購入しない理由や、「購入した顧客はなぜ購入したのか」といった購入した理由を把握することができます。商品のパッケージや価格、アプリのUIや機能など、どこに課題がありどこが良いかなどを把握することが可能です。結果をクロス集計することでどの商品がどの性年代で満足度が高いか低いかなどを把握することができます。また、NPSという指標をアンケートで測ることで、顧客満足度を調査することができます。 - 顧客によるレビューの分析
ECサイトや様々なプラットホームには顧客によるレビューがあります。このレビューをテキスト分析することでどのようなキーワードが多く使われているか、関連性の高い単語は何かを明らかにすることができます。
またソーシャルメディアにもレビューがあります。ソーシャルメディアの分析では、どのようなトレンドが生まれているか、どのような商品やサービスが人気を集めているかを把握することができます。
これらを活用することにより、顧客の要望や意見を把握することで、顧客満足度を向上させるための商品やサービスを開発することができます。 - 顧客の履歴の分析
顧客の購買履歴やWebサイト閲覧履歴などを分析することで、顧客が顕在化させていない潜在的なニーズを把握することができます。例えば、バスケット分析では、顧客が一緒に購入する商品を分析して、関連する商品を発見し顧客が潜在的に必要としている商品を発見することができます。これにより、関連商品のレコメンド・商品セット販売・関連商品の購入促進のためのクーポン発行などに役立ちます。
データ分析の進め方
データ分析をビジネスに活かすためには、どのようにデータ分析を進めればよいでしょうか。理想にはなりますが、下記の順番で進めるのがよいのではないかと考えています。
課題を設定する
まずは課題を設定する必要があります。できれば具体的な課題を設定するとよいです。例えば、「施策の効果がわからない」よりも「施策実行によるDAU・PVへの影響がわからない」、「予算削減により施策のターゲットを絞りたいが、施策の最も効果的なターゲットの集団がわからない」などできるだけ課題を詳細にする必要があります。
課題設定にあたっては、以下の5W1Hを意識すると効果的なケースもあります。
- What: 何が課題なのか
- Why: なぜそれが課題なのか
- Who: 誰にとって課題なのか
- When: いつ課題が発生しているのか
- Where: どこで課題が発生しているのか
- How: どのように課題を解決すればよいのか
その課題に対してどのような意思決定をするかを想定しておく
意思決定は非常に複雑で様々な要因に鑑みて総合的にすることが多いと思います。そのため、様々な角度からデータ分析を行い結果が出そろってからどのような意思決定をしようか考えたくなります。しかし、データ分析は時間もコストもかかります。そのため、どのような意思決定をするかをあらかじめ想定しておくことが重要です。例えば、施策を実行してもDAU・PVが予算に対して目標を達成していない場合は中止する、またはより効果的な施策の改善案を考えるなどです。
何がわかると意思決定できそうかを考える
より早くより適切なデータ分析をするためには「何がわかると意思決定できそうか」を設定する必要があります。「今まで分析したことがない」や「興味がある」などは面白いかもしれませんが、それを知っても意思決定ができない場合はビジネス課題を解決することはできません。例えば、アプリのユニークユーザ数の向上がビジネス課題を例に考えてみます。ユーザの性別毎のユニークユーザ数を分析した結果、男性3割・女性7割であることが分かったとしても、施策やUIの変更につなげる意思決定をすることができず、ビジネス課題を解決できなければ、データ分析が役割を果たしたとは言えません。また、意思決定者がユニークユーザの性別の割合がどのような結果であっても、それによって何かしらの意思決定をするつもりがなければ分析をしても意思決定には貢献することは少ないです。そのため、データ分析を進める間に「何がわかると意思決定できそうか」を考える必要があります。
分析設計を考える
「何がわかると意思決定できそうか」を考えた後は、どのような分析をしたら知りたいことが適切にわかるかを考えます。これは「適切な分析設計を考える」と同じ意味です。分析設計は重要です。分析設計は、分析結果の妥当性と再現性に影響を与えます。詳細については良書がたくさんありますのでそちらを参考にしてください。また、分析結果を関係者が理解できるかも考慮して分析設計を考える必要があります。難しい分析手法で解釈が難しい場合は関係者が分析結果を正しく解釈できない可能性があります。また、難しい分析手法が優れているわけではなく、簡単な分析手法でも意思決定をするうえで十分であり、ビジネスの課題が解決されれば問題ありません。
分析設計を考える際には取得可能なデータについて調査する必要があります。適切な分析設計を考えても、取得不可能なデータがあり適切な分析設計ができない場合は、別の分析設計を考える必要があります。必要な期間・種類のデータが取得できるかを調査します。また、欠損が多いと分析結果と解釈に大きな影響を与えます。データがあると思っていても欠損が多く分析に耐えられないこともあるので注意が必要です。
分析をする
分析に使うツールは実施予定の分析手法・スケジュール・分析者のスキル・データ量などを考慮して決めると良いです。
代表的な分析ツールの特徴をご紹介します。
Excel:汎用性の高い表計算ソフト。データ集計、グラフ作成・基本的な統計手法を用いるときなどに適しています。Excelは広く利用されており、多くの人との共有が容易です。データ量が多くなると処理速度が遅くなり、複雑な分析が難しいことがあります。
Python:汎用性の高いプログラミング言語。データ加工・データ分析・機械学習などに適しています。プログラミング言語であるため習得までに時間がかかり、利用するために環境を構築する必要があるため、初心者にとってはハードルが高い場合があります。しかし、一度習得して、環境構築もできるようになれば、データ分析専用のライブラリが豊富に揃っており、高度な分析や機械学習にも対応できます。
SQL:大規模なデータセットを扱う場合にも高速・効率的にデータを処理することが可能です。データ量が多くなり、データベース言語といわれるデータベースを操作するためのクエリを記述する必要があり習得まで時間がかかることがあります。Pythonと比較すると習得しやすいと思います。分析対象となるデータがリレーショナルデータベースに格納されている必要があります。
R言語:統計分析に特化したライブラリが豊富で、統計モデリングの構築・評価が容易に行えます。また、活発な統計分析コミュニティが存在し、情報収集や問題解決に役立ちます。R言語を習得する必要があるため、初心者にとってはハードルが高い場合があります。
分析結果をまとめる
分析を実行した後は、結果をわかりやすくまとめます。わかりやすくまとめるためには、簡潔な文章で事実を記載することが重要です。冗長な表現や回りくどい言い回しを避ける、二重否定を使わないようにします。また、相手の専門知識や理解度を考慮することも重要です。結果を表やグラフにまとめることでより理解しやすくなります。グラフを作成するときは認知負荷が低くなるように不要な要素を取りのぞく必要があります。また、相手に伝わりやすい表現を選択することも重要です。円グラフや第2縦軸は認知負荷が高いので選択しないほうが良いです。
レポートを作成する
結果を出しただけでは意思決定はできません。結果から推察や洞察を加えて意思決定に役立つレベルにまで高めたレポートを作成する必要があります。レポートを活用するのは意思決定者です。意思決定者がどのようなことを考えているか、組織の目的や基本戦略を理解して、どのような意思決定をしようとしているかを理解する必要があります。これは、意思決定者の望む結果に沿ったレポートを作成するということではありません。実行可能で組織の目的と基本戦略に合うレポートを作成するというものです。実行不可能なアクションを提案することや基本戦略に合わない結論では意思決定を支援することは難しいです。普段から意思決定者と密にコミュニケーションを取り、組織の目的や基本戦略を理解しておくことが重要です。
また、データ分析の結果を飛躍して解釈しないことも重要です。ビジネスでは様々な制限の中でデータ分析をすることが多いと思います。その制限が意思決定に大きな影響を与えると判断すれば、実施したデータ分析にはどのような制限があるか、その制限が具体的にどのようなことなのかを意思決定者に伝える必要があります。分析に用いるデータの種類が少ないことや偏りのあるデータであること、使用した分析手法の特性や限界点、分析を行った際の前提条件を明確にして条件が変化した場合の影響について意思決定者に伝える必要があります。結果から飛躍した解釈をしないように誠実にデータ分析の結果と向き合う必要があります。
意思決定者に報告をしてフィードバックをもらう
意思決定者など関係者に報告をします。報告の際に気を付けることの1つに「分析結果に対する説明を十分に行う」があると考えます。分析の目的と背景の明確化、分析手法とデータソースの明記などです。特に分析手法は専門的な内容になり、使用した手法の基本的な考え方や仕組みを簡潔に説明することや、分析対象にその手法が適切であることを説明する必要があります。
また、報告で終わるのではなく、意思決定者や現場の方から分析のフィードバックをもらうことが重要です。レポートは実際に役に立ったのか、役に立たなかった場合はなぜなのか、どのような分析をしたら役に立ったのかをヒアリングします。良かった点、悪かった点をまとめて、もう一度修正して分析をする、または次回の分析に活かすことが重要です。
具体的な分析手法
データ分析をビジネスに活用するためには、適切な分析手法を選択する必要があります。一例にはなりますが、代表的な分析手法について紹介します。
施策の効果検証
キャンペーンなどの施策の効果検証にはA/Bテスト・回帰分析・傾向スコアを用いた分析・差分の差分法・回帰不連続デザインなどがあります。これらは正しい比較をするうえで、何が妨げになっているかによって使い分けます。適切な効果検証の分析手法を用いることで施策の効果を適切に評価することができます。
テキストアナリティクス
VOCやサービスの口コミなど文章で記載されているデータに対する分析がテキストアナリティクスです。テキストアナリティクスを用いることで顧客のニーズや要望をより理解することができ、サービス向上やマーケティングの意思決定に貢献します。
機械学習による意思決定支援
施策を行う上で十分な予算があれば良いですが、限られた予算の中で施策を実施することが多いと思います。そのため限られた予算の中で効果の高いと予測されたお客様を優先して施策を実施したいときは、機械学習と呼ばれる手法を用いることで実現できます。また、施策がなければ購入するが、施策を実施すると購入しなくなるお客様もいます。このようなお客様の特徴を明らかにすることも機械学習を用いることで実現できます。
アンケート分析
アンケート調査で得られた回答データを分析し、調査対象となる集団の特徴や傾向を明らかにすることを目的に行われます。市場調査、マーケティング、顧客満足度調査、社内アンケートなど様々な場面で用いられます。
アンケート分析には様々な分析手法があります。代表的な手法をいくつか紹介します。
- 単純集計
各質問項目に対する回答の頻度や割合を集計します。回答者の人数、回答割合も重要な算出項目です。 - クロス集計
複数の質問項目を組み合わせた分析を行います。例えば「年代別と性別ごとの購入頻度」をクロス集計することで年代や性別による購入頻度の違いを分析することができます。単純集計ではわからない、属性や別の質問項目との関連を分析することが可能です。 - クラスター分析
回答者をいくつかのクラスター(グループ)に分類して、各クラスターの特徴を分析します。分類方法として階層型クラスター分析やKMeans法などの非階層型クラスター分析があります。
まとめ
データ活用の一つであるデータ分析について、メリット・進め方・具体的な手法の一例をお伝えしました。
データ分析をビジネスに活用するためにはビジネス課題は何か・どのような意思決定をしたいかを考えて、適切な分析手法を選択し、結果から推察や洞察を加えて意思決定に役立つレベルにまで高めたレポートを意思決定者に提供することが重要です。
データアドベンチャーカンパニーは、ビジネス課題を解決するという強い気持ちをもってデータ分析をするデータアナリスト・データサイエンティストが在籍しています。もし、データ収集~分析~活用までお困りごとやご相談などあればデータアドベンチャーカンパニーにご相談ください。
\ データ活用についてのご相談はメンバーズデータアドベンチャーまで /
\ 相談する前に資料を見たいという方はこちら /
データ分析と聞くと高度な計算や知識が必要と身構えてしまいます。多少の知識は必要になりますが、”手早く簡単に数字の動向を調べたい” など目的によっては特別な分析ツールや知識を大量に要せずとも可能な場合が多くあります。
多くの方になじみのあるExcelでも可能な分析もまた、多くあります。普段使いの延長で操作可能なものが多いため、普段データに触れない方でも比較的簡単に分析できるかと思います。以降Excelを使った分析のメリット・デメリット、できることや機能の紹介をしていきたいと思います。
執筆者のご紹介
くりた
所属:株式会社メンバーズ メンバーズデータアドベンチャーカンパニー アナリスト事業部 データアナリスト
データアナリストとしてメーカーや、スーパーなどの小売業の分析を行っています。具体的には売上の分析、施策の効果検証や設計に携わっています。
分析ツールの一つである Tableau を中心に扱い、膨大なデータから目的となるデータの抽出・分析、可視化やダッシュボード化を行っています。
その他ツールではExcelやPythonを状況に応じて活用しています。
経歴
メーカーの営業を経て2023年にメンバーズ入社
顧客企業にデータアナリストとして常駐し施策効果検証や顧客分析、データ活用の内製化を支援。
目次
01.| そもそもExcelでデータ活用は可能なのか?
02.| Excelで分析を行う際のメリットとデメリット
メリット
デメリット
03.| Excelでデータの活用を行う場合のポイント
04.| データ活用の際備えておくべきExcelの基礎知識とは
05.|売上データ分析をExcelで行う際の方法は?
分析のためのデータ加工
Excelで代表的な分析
06.|Excelでは難しいデータ分析はある?
複雑な分析の実施
データ量の制限
07.|まとめ
そもそもExcelでデータ活用は可能なのか?
Excelは、データの整理・加工、可視化、分析を強力にサポートするツールとして、幅広い分野で活用されており、多くの人にとってなじみ深いツールです。膨大なデータから知見や傾向を導き出すために、Excelの活用は有用な手段だと考えます。
しかし、Excelでの分析にはメリット・デメリットも存在します。
Excelで分析を行う際のメリットとデメリット
メリット
- 多くの人が使用経験のあるツールであり、導入コストも低い
Excelの関数はデータ分析を目的としていなくとも使用経験がある方が多く、今まで培った経験が活きやすいです。他の分析ツールを使用するには言語の習得等・ツールの操作理解等が必要になることが多く、習得コストが高いですが、Excelでは普段使いの延長にあたる部分もあり習得コストが比較的少なく済むと考えます。
また、すでに導入されている方や企業も多く、使用までのコストが少なく済みます。 - 視覚的な確認が容易
分析用のツールでは、算出ロジックは出力されずあくまで結果の数値のみが出力されることが多いです。しかしExcelでは関数を用いて数値を出力した際に算出ロジックも残ります。実際に関数にどの数値を用いたかが色付けされるため視覚的にも易しいと感じます。
デメリット
- 膨大なデータや処理に不向き
Excelにはデータの最大数が決まっており膨大なデータには対応できない場面があります。
また、データ量が許容範囲であっても処理速度が遅くなることがあります。
基礎的な分析・可視化機能は備わっていますが、複雑な分析・可視化には不向きというデメリットもあります。
Excelでデータの活用を行う場合のポイント
当然ですがデータ分析専用のツールを使用したほうが基本的に処理も速く、分析可能な内容も多いです。Excelよりも可視化に優れたツールも多く、簡単かつ効果的な可視化を行うことも可能です。
分析的な機能で劣る点が多いExcelですが、素早くデータを分析し、傾向を把握をする際には非常に有効です。また、高度な計算を要しない分析を行う際にも、敢えてツールに読み込ませる必要なく手元で簡単に処理できる利点もあります。
ただし、Excelは社内でバージョンが統一されていない場合があります。分析に使用する関数によっては互換性がなく機能しない場合があります。
Excelを使用するうえでバージョンの違いは注意しておくべき点です。
データ活用の際備えておくべきExcelの基礎知識とは
Excelには、データ分析を簡単に、かつ効率的に行うための様々なツールが備わっています。代表的なツールは以下の通りです。
- データ分析ツール
相関分析、回帰分析、検定など、統計分析を行うためのツールがセットになっています。
各分析手法の採択仕方や出力結果の解釈の仕方は学習する必要がありますが、使い方は易しく、算出に必要なデータの範囲を指定するだけで出力可能なことが多く便利です。 - ピボットテーブル
ピボットテーブルは、データを多角的に分析し、集計や比較を簡単に行うことができる機能です。
特に任意の粒度でデータをまとめ、簡単な集計関数で集計を行う機能は非常に便利です。データをまとめた場合もドリルダウンで要素の詳細を確認することも可能です。
操作についても基本がドラッグ&ドロップで行うことができ、操作したそばから反映・出力されるため直観的・視覚的に操作が可能です。 - csvファイルの読み込み
売上データなどデータの受け渡しにはcsvファイルが使用されることがあります。
csvファイルをダブルクリックし、直接Excelで開いてしまうと実際とは異なるデータが表示される場合があります。
よく起こることが “数字の0落ち”や ”数字の日付化” です。
特に各種コードなどで頭の0落ちは見逃しやすく、事実とは異なった示唆を与えてしまう可能性があるため注意が必要です。
csvファイルはテキストエディタを介して開く方法やPower Queryの使用により正しくExcelで読み込むことができます。
売上データ分析をExcelで行う際の方法は?
分析のためのデータ加工
手元にあるデータが目的の分析に適していない場合があります。目的に応じてデータを加工する必要があります。目的がはっきりとしている場合、不要な情報は取り除き、必要な情報は足すといった処理を行います。
主に行う処理をいくつか紹介します。
- 必要情報の結合
売上と顧客ID、顧客IDごとの住所が別のデータにあり、住所ごとの売上を分析したい場合、二つの情報を結ぶ必要があります。
vlookup関数等の使用により実現することができます。ただし今回のケースでいう ”顧客ID” のようにつなぎたいデータ間で同じ情報を持つことが条件です。
vlook関数以外の関数やPower Queryの使用でも情報の補完・結合は可能です。 - フラグ処理
”A” という商品を買った顧客、〇〇円以上購入した顧客、クーポンを利用した顧客など分析を行いたい対象が明確な場合。
Excel関数の ”IF” を使用し、条件に該当すれば ”1” 、該当しなければ ”0” などを付与することでいわゆる〇×情報を加えます。
ピポットテーブルで分析を行う際にも対象群と非対象群ごとの集計が簡単にできたり”回帰分析” に転じたりと分析の幅が広がります。
フラグの組み合わせにより ”〇〇円以上購入” かつ ”クーポンを利用した顧客” などの抽出も容易になり、顧客や商品の深堀を行い属性や特徴の分析につながります。
Excelで代表的な分析
- デシル分析
デシル分析はExcelを使用し誰でも簡単にできる分析の一つです。
顧客を売上の高い順位に並べ10等分し、各グループの情報を分析する手法です。
10等分に細分化することで各グループの特徴を正確に理解・把握することが可能です。特に売上の高い上位グループの売上増加を目的とした場合、対象となるグループ傾向に合致するような施策を行う等、より効果的に顧客へアプローチすることができます。
このようにデシル分析を行うことでより効果的なマーケティング施策検討が可能になります。
ただし、今回売上を基準に10分割したように、一つの情報のみで顧客を細分化しており、その他の情報は排除されている点は評価の際考慮しなければなりません。 - 相関分析
Aが変化するとBも伴って変化するか否かを明らかにし、比較する2つの間に特徴があるか否かを簡単に把握することが可能な分析です。
例として冷凍食品の品揃えが多い店舗は店舗の売上も高くなる傾向があるかないかをおおまかに判断する際に使用します。
判断の指標となる相関係数の算出はExcelに備わっている ”分析ツール” の活用や ”Excel関数” の使用で求められます。相関係数は-1から1の間で表現され、この数字が-1と1のどちらかに寄っているかで判断されます。
冷凍食品の品揃えが多ければ売上も多いことが結果として出たので各店舗冷凍食品の品揃えを増やし売上拡大を図ろうという判断の材料になります。
一方、冷凍食品の品揃えが多いのは単純に店舗規模が大きく売上も多かっただけで売上の大小には冷凍食品の品揃えは直接関与していなかった、といったように本当に2つの要因が原因と結果の関係にあるかの判断も重要です。 - ダッシュボード化
あらかじめ関数を組んでおき、所定のフォーマットでデータを張り付ければすべて自動で計算・グラフ化を行うことができます。Excelフォーマットを作成することで定常作業で毎回関数を打ち込み作成していた作業もデータの貼り付けだけで済むようになります。
Excelでは難しいデータ分析はある?
複雑な分析の実施
簡単な関数の組み合わせでは実現しない分析や、Excelに備わっていない複雑な分析を行うには分析専用のツールの使用が好ましいと考えます。
データ量の制限
一番の難点はデータ量の制限にあると思います。データベースからデータを抽出する際、可能な限り余分なデータを排除したりしてデータ量を軽くする必要があります。場合によってはデータの再抽出を行う必要が出たりと分析がスムーズに運ばないことがあります。また、データ量の制限以内でも数十万行を超えるような大きなデータを扱う場合にはExcelの処理速度が大幅に低下するなど膨大なデータを扱う際にも分析専用のツールの使用が必要になってきます。
まとめ
大まかに素早くデータの傾向をつかむ際にはExcelで十分対応可能な場面が多々あります。特にExcelは業務環境に標準装備されていることも多く導入-習得までのコストが分析ツールの導入-習得に比べると少なく済む点も魅力的です。
一方で膨大なデータを扱う際や高度な分析を行うにはExcelだけでは荷が重い場合があり、分析専用のツールを採択するなど、目的に合わせて使用していくことも重要であると考えます。
普段の業務でExcelを使用している方も使用していない方も分析の取っ掛かりとしてExcelは十分な役目を果たせると思いますのでぜひチャレンジしていただければなと思います。
\ データ活用についてのご相談はメンバーズデータアドベンチャーまで /
\ 相談する前に資料を見たいという方はこちら /
総務省(2020)「デジタルデータの経済的価値の計測と活用の現状に関する調査研究※1」によると、データ利活用の効果を享受するには、データ活用を高度化することが有効であるとの分析結果が得られています。高度化とは、難解な分析手法を用いることでは必ずしもないと思っています(手法を知っていることは大事ですが)。難解な手法を用いるというよりかは、適切な課題設定とそれに対応した分析手法とデータ選定を行い、分析結果を解釈して意思決定することだと考えています。本記事では、データ利活用を効果的に行うために何をどのように行うべきなのかを以下6つのステップで紹介していきます。
①データ活用とは
②データ活用のメリット
③どのように利用するデータを決めるのか
④データ生成過程を確認する
⑤分析手法ってどうやって決めるの?
⑥分析結果をどのように解釈し意思決定に活用するのか?
※1 出典:「令和5年版情報通信白書」(総務省)
https://www.soumu.go.jp/johotsusintokei/whitepaper/ja/r05/pdf/n2100000.pdf
licensed under CC BY 4.0 https://creativecommons.org/licenses/by/4.0/deed.ja
執筆者のご紹介
所属
サービス開発室 秋山
業務内容
データ利活用に関する試験研究/新規事業開発案件における企画・推進をリードしています。GIS(地理情報システム)や機械学習・深層学習モデルなどの技術を活用したり、評価指標設計をしたり、プロジェクト方針の意思決定をしたりしています。
経歴
経済学部卒業後、外資系SIerにて生命保険事業におけるEUCシステムの設計・構築とプロジェクトリードを経験しました。社会人経験後、一橋大学経済学研究科にて産業組織論や応用ミクロ経済学、計量経済学を専攻し、ジョイントベンチャーなどの企業組織形態の最適化に関する理論分析や企業カルテル・談合に関する実証分析などを行ってきました。大学院卒業後、株式会社メンバーズ データアドベンチャーカンパニーに入社した。
目次
01.| データ活用とは
02.| データ活用のメリット
03.| どのように利用するデータを決めるのか
04.| データ生成過程を確認する
05.| 分析手法を決定する
06.|分析結果の解釈と意思決定への活用
07.|まとめ
データ活用とは
データ活用とは、収集された情報やデータを分析し、分析結果に基づいて意思決定を行うプロセスを指します。現代のビジネス環境において、企業は大量のデータを収集し、それを有効に活用することで競争優位性を確立しています。データ活用の具体的な例として、顧客の購買履歴を分析してマーケティング戦略を最適化したり、センサーからのデータを使って製造プロセスの効率を向上させることが挙げられます。これにより、企業は顧客のニーズをより正確に把握し、より効果的な製品やサービスを提供することが可能になります。また、データ活用はビジネスだけでなく、医療や教育、公共サービスなどさまざまな分野で重要な役割を果たしています。
データ活用のメリット
データ活用には多くのメリットがあります。まず、データに基づく意思決定は直感に頼るよりも精度が高く、リスクを低減する効果があります。例えば、売上データを分析することで、需要の予測精度が向上し、在庫管理が最適化されるため、コスト削減が可能です。また、顧客データを活用することで、顧客の嗜好や行動パターンを理解し、パーソナライズされたサービスを提供することができます。これにより、顧客満足度の向上やリピーターの増加が期待されます。さらに、データを活用することで、新しいビジネスチャンスの発見やイノベーションの促進も可能になります。たとえば、ソーシャルメディアのデータを分析することで、消費者トレンドをいち早くキャッチし、新製品開発に活かすことができます。このように、データ活用は組織全体の効率性や競争力を高めるための重要な手段となっています。
どのように利用するデータを決めるのか
利用するデータを決定する際には、まず解決すべき課題や達成したい目標を明確にすることが重要です。次に、その課題や目標に対して最も関連性の高いデータを特定します。それに加えて分析対象(顧客、企業など)の行動原理を整理しておくこともデータ選定の上で役立つと思います。
たとえば、顧客満足度を向上させたい場合、顧客のフィードバックや購買履歴、ソーシャルメディアのコメントなどが有用なデータとなります。また、データの品質も重要な考慮点です。信頼性の高いデータソースから取得し、データが最新で正確であることを確認する必要があります。さらに、データの入手方法やコストも考慮に入れる必要があります。必要なデータが社内に存在しない場合、外部から購入することも検討するべきです。最後に、データの形式や構造も考慮し、分析に適した形であるかを確認します。
データ生成過程を確認する
データ生成過程を確認することは、データの信頼性と品質を確保するために重要です。データは通常、収集、処理、保存の各ステップを経て生成されます。まず、データ収集の段階では、センサー、トランザクションシステム、ソーシャルメディアなど、さまざまなソースからデータが収集されます。次に、収集されたデータはクレンジングやフォーマット変換などの処理が施され、分析に適した形に整えられます。この段階で、データの誤りや欠損を修正し、一貫性を持たせることが求められます。最後に、処理されたデータはデータベースやデータウェアハウスに保存され、後の分析に利用されます。この過程で、データの整合性やセキュリティも確保されるべきです。また、データの生成過程全体を監査し、記録を残すことで、後からデータの出所や変更履歴を確認することが可能となります。
分析手法を決定する
分析手法を決定する際には、分析の目的や対象データの特性を考慮することが重要です。以下に、分析手法を決めるためのステップを示します。
- 目的の明確化: まず、何を明らかにしたいのか、どのような問題を解決したいのかを明確にします。例えば、売上の予測を行いたいのか、顧客のセグメンテーションを行いたいのかによって、適用する手法が異なります。
- データの特性評価: 次に、データの種類(数値データ、カテゴリデータ、テキストデータなど)、データの量、欠損値の有無などを評価します。このステップでデータの前処理が必要かどうかも判断します。
- 手法の選択: 目的とデータの特性に基づいて、適切な分析手法を選択します。例えば、数値データの相関関係を調べるためには回帰分析が適しており、カテゴリデータの分類には決定木やランダムフォレストなどの機械学習アルゴリズムが有効です。以下にいくつかの代表的な分析手法を紹介します。
- 回帰分析: 連続変数の関係をモデル化し、予測を行うために使用されます。
- クラスター分析: データをグループに分け、パターンを見つけるために使用されます。
- 決定木分析: データの分類や予測を行うために使用されます。
- 時系列分析: 時間の経過に伴うデータの動向を分析し、予測を行います。
- テキストマイニング: テキストデータを解析し、情報を抽出するために使用されます。 - モデルの構築と評価: 選択した手法を用いてモデルを構築し、データに適用します。モデルの性能を評価するために、適切な評価指標(例えば、平均二乗誤差、正確度、F値など)を使用します。クロスバリデーションやトレーニングセットとテストセットの分割なども行い、過学習を防ぐことが重要です。
- モデルの適用とチューニング: 最終的に選んだモデルを適用し、必要に応じてパラメータの調整やアルゴリズムのチューニングを行います。これにより、モデルの精度やパフォーマンスを向上させることができます。
分析結果の解釈と意思決定への活用
分析結果を解釈し、意思決定に活用するためには、以下のステップを踏むことが重要です。
- 結果の確認: まず、分析結果を詳細に確認します。これは、グラフや表、統計的指標などを用いて視覚的に理解しやすい形で提示されることが望ましいです。結果が期待通りかどうか、異常値やパターンがないかをチェックします。
- 結果の解釈: 分析結果をビジネスの文脈に照らして解釈します。例えば、売上予測モデルの結果から、特定の季節に売上が増加する傾向が見られた場合、その理由を検討します。顧客セグメンテーションの結果から、どの顧客グループが最も利益をもたらすかを考察します。
- 意思決定への反映: 解釈した結果を基に、具体的なアクションプランを策定します。例えば、売上が増加する季節に向けて在庫を増やしたり、利益率の高い顧客グループに対してターゲットマーケティングを実施したりします。重要なのは、結果をどのようにビジネス戦略に組み込むかを明確にすることです。
- フィードバックと改善: 分析結果に基づいて行動した後、その結果をモニタリングし、効果を評価します。期待通りの成果が得られたかどうかを確認し、必要に応じてアプローチを調整します。これにより、データ分析プロセスは継続的に改善され、より高い精度と効果を持つようになります。
- コミュニケーション: 分析結果を関係者に分かりやすく伝えることも重要です。専門的な用語や複雑な統計情報を避け、シンプルで具体的な説明を心がけます。これにより、組織全体での理解と合意が得られやすくなり、データに基づく意思決定がスムーズに進行します。
これらのステップを踏むことで、データ分析の結果を効果的に活用し、組織のパフォーマンスを向上させることができます。
まとめ
データ活用とは、収集したデータを分析し、分析結果を基に意思決定を行うプロセスです。現代のビジネス環境では、企業が大量のデータを有効活用することで競争優位性を得ることが求められています。データ活用には多くのメリットがあります。データに基づく意思決定は直感に頼るよりも精度が高く、リスクを低減します。例えば、売上データの分析で需要予測精度を高め、在庫管理を最適化することでコスト削減が可能です。さらに、顧客データを活用することでパーソナライズされたサービス提供が可能となり、顧客満足度やリピーターの増加が期待されます。また、データ分析により新たなビジネスチャンスやイノベーションの促進も可能です。
データ分析手法を決定するには、目的や対象データの特性を考慮することが重要です。まず、解決すべき課題や目標を明確にし、関連するデータを特定します。次に、データの品質や入手方法を考慮し、適切な形式に整えます。分析手法は目的とデータの特性に応じて選択し、モデルの構築と評価を行い、必要に応じてチューニングを行います。最終的に、分析結果をビジネスの文脈で解釈し、具体的なアクションプランを策定して意思決定に活用することでデータ活用を促進できます。
\ データ活用についてのご相談はメンバーズデータアドベンチャーまで /
\ 相談する前に資料を見たいという方はこちら /
今回の記事では、マーケティング業務にデータを活用していくためのステップをお伝えします。
執筆者のご紹介
髙木
所属:株式会社メンバーズ メンバーズデータアドベンチャーカンパニー アナリスト事業部、データアナリスト
顧客企業に常駐し、現在は学習塾の申込情報を基に生徒の行動分析や各講習会の効果検証、データ分析基盤の構築を担当
経歴
大学院で分析手法の開発に関する研究を経て、2022年にメンバーズに新卒入社。
入社後、データアナリストとしてECポータルサイトのデータ抽出、加工、可視化といった基本的な業務に従事。2023年から現職。
目次
01.| データ活用とは?
データ活用の定義
マーケティングデータを活用するメリット
02.| データ活用はどう進めるべきか?
03.| マーケティング部署での活用事例
04.| まとめ
データ活用とは?
データ活用の定義
私が考える「データ活用」とは「データを使って良い、悪いの判断ができる」ようになっていることです。マーケティング業務においては、商品やサービスが売れる仕組みを作るために、いろいろな情報をかき集め、どの商品・サービスが良いのか、悪いのかを判断したうえで、マーケティング施策を実行するということです。
マーケティングデータを活用するメリット
「マーケティングデータ」の活用に限ってお話しすると以下のメリットがあります。
- 施策の効果検証が可能となり継続可否判断ができるようになる。
- 新規施策として有効なアプローチ方法の示唆出しが可能になる。
- 業務効率化(生産性が向上する)。
- 顧客のCX(カスタマーエクスペリエンス)を向上させることができる。
上記のようにデータ活用は事業の拡大や収益性の向上にもつながります。
データ活用はどう進めるべきか?
データ活用の流れは以下の通りです。
① 分析の目的設定
② データの収集
③ データ分析
④ 結果の活用
一つ一つを素早く丁寧に行っていけば、答えは見えてくるものだと思います。
一回やったら終わりで次の施策の分析に移るというものではなく、①~④を繰り返しサイクルを回すことで、分析のクオリティが上がり、マーケティング施策の効果が向上します。
例えば、週に1回DMを送る施策があれば、週次で分析を繰り返し、年に1回の特別なイベントを開催するのであれば、その開催日までにその施策がうまくいくため要因、根拠を明らかにし、その成功率を上げるために何度も分析を繰り返し行うことで、社内の多くの人たちを巻き込んだマーケティング施策を高い成功率で行えるかもしれません。1回で答えを出すのではなく、根気強く何度も分析を繰り返すことで、次第に成功の道筋が見えてきます。
分析の目的を曖昧にせず、データ分析を行えるようになることがデータの活用の第一歩です。
マーケティング部署での活用事例
ここからは、私が普段マーケティング部署において、データアナリストとしてどのようにデータ活用しているか話していきたいと思います。
活用事例
私が実際に行った分析事例をご紹介します。予備校を運営する企業において、少子化による高校生の減少と、大学・総合型選抜の増加による現役志向の学生が増えるという脅威に対して、現役生向けの学習アプリの売上を向上させ、課題を解決するための分析です。既存事業の現状の分析結果は以下でした。
- 浪人生と比べて現役生の人数は少なく、特に高校1,2年生の人数が少ない
- 高い偏差値の生徒が多い
この学習アプリは現状あまり獲得できていない「偏差値40〜55帯の現役生をターゲット」にすることになりました。
次に、オープンデータを使い、ターゲットのボリュームや特徴を推定します。地理的変数、人口動態的変数、心理的変数、消費者行動変数という4つの切り口で見ていきます。結果は以下の通りです。
地理的変数
アプローチできる主要都市の学生46.38%
人口動的変数
家族構成ー2人親:79.5% 1人親20.5%
心理的変数
勉強に対する考え方
一生懸命勉強すれば、将来良い暮らしができる 「そう思う」は10年前より-9.2pt
受験勉強は本当の勉強とは言えない 「そう思う」は10年前より+11.6pt
消費者行動変数
趣味ー回答が30%をこえるもの
・成績・受験
・友達付き合い
・音楽
・インターネット動画
・漫画
・ゲーム
・おしゃれ
・将来のこと
これを元に、ターゲットがどんな考えや習慣を持ち、どんな行動をするのかなどを考え、施策を検討、実施していきました。
上記の流れを繰り返し行うことで、実施した施策の効果検証を行うことができました。
また、この取り組みによって他支店や他部署でもデータ活用の重要性が少しずつ認知され、既存部署以外でもダッシュボード作成や更新の自動化・保守運用の依頼が増加しました。
まとめ
今回はデータ活用の基本と実際の活用事例をお話ししました。
データは分析するのみでは売り上げや利益を生み出すことができませんが、分析結果を活用し施策に落とし込み、更にその施策の効果検証を実施することで成果として事業成長に貢献することができます。
そのため繰り返し根気強く分析をしPDCAのサイクルを回すことが重要です。
もし根気強くやっていても成果が出ない、または分析の仕方があっているのかわからない、などのお悩みがあれば専門家への相談も視野に入れるとよいでしょう。
\ データ活用についてのご相談はメンバーズデータアドベンチャーまで /
\ 相談する前に資料を見たいという方はこちら /