生成AIの普及に伴い、現在ではあらゆる企業でAI導入に向けて動き出しています。
しかし、「AIを導入したものの、期待した成果が出ない」という声も少なくありません。AIデータ分析を成功させる鍵は、目的に合わせた適切なプロセスを理解し、実行することにあります。本記事では、AIデータ分析を成功に導くための具体的なステップと、プロジェクトを始める前に知っておきたい「よくある落とし穴と解決策」を分かりやすく解説します。
▶目次
01.AIを使ったデータ分析とは?
01-1. AIデータ分析の定義
様々な解釈がありますが、ここでは「用途・目的に合ったAIを用いて、予測や分類などを行うデータ分析手法」と定義します。
中でも「用途・目的に合ったAIを用いて」という部分が非常に重要であり、必要に応じて用途・目的に即したAIを作るところから分析を始めなければなりません。
01-2. 従来の分析との違い
人間による手動分析も非常に数多くの手法があります。例えば、売上の前年比を算出して結果の裏には何の影響があったのか?を様々な数字から仮説を立ててみたり、数字をグラフにして可視化して要因分析してみたりなどが挙げられます。これらに共通する点は、人間が探索的に要因を分析している事。言わば 手動分析 です。
一方でAIは、入力されたデータから自律的に特徴を見つけ出し学習を行います。したがって、AIが結論を導き出した時には既に分析が完了しております。言わば 自動分析 です。
しかし、AIの思考プロセスは人間には見えにくく、「ブラックボックス」と化してしまうことがあります。そのため、ビジネスの現場では「予測精度は高いが、なぜその結論に至ったのか根拠が分からず、重要な意思決定に使いづらい」という課題が生じがちです。その中でも、一部のAIモデルでは、モデルの考えを解釈するための機能を持っているため、それらのモデルによるAIを用いる事でAIによる分析根拠を得る事ができます。これを XAI(説明可能なAI) と呼びます。XAIにより、ユーザーが 持ち合わせていない知見をAIから得る事ができる 場合もあります。
ただし、扱うデータやモデルが複雑な場合には分析根拠を解析するのが困難なため、XAIを実現できる範囲は限定的です。例えば扱うデータが画像や音声といった非構造データの場合、対応できるモデルも深層学習といった複雑なものになるため、分析根拠の解析は難しくなります。
01-3. AIデータ分析の種類
AIデータ分析の種類は、AIが扱う問題の種類から直結します。そのため、ここではAIが扱う問題の種類について説明します。AIが扱う問題にも様々な種類がありますが、代表的な3点を紹介します。
<予測(回帰問題)>
過去のデータから学習し、将来の数値を予測する手法 です。「来月の売上はいくらか?」「キャンペーンによる販売数は何個か?」といった問いに答えるために使われます。
【活用例】
- ・店舗ごとの売上高予測
- ・Webサイトのアクセス数予測
- ・商品の需要予測と在庫最適化
<分類(分類問題)>
データを特定のカテゴリに仕分ける手法 です。「この顧客はAとBのどちらのグループか?」「この取引は正常か異常か?」といった判断を行います。
【活用例】
- ・顧客がサービスを解約するかどうかの予測(チャーン予測)
- ・クレジットカードの不正利用検知
- ・迷惑メールフィルター
<クラスタリング(分類問題)>
明確な正解がないデータの中から、AIが自動的に似た性質を持つグループ(クラスター)を見つけ出す手法 です。人間が気づかなかった新たな顧客セグメントの発見などに繋がります。
【活用例】
- ・顧客の購買傾向に基づいたセグメンテーション
- ・アンケート結果のグループ分けによるインサイト抽出
- ・類似した特徴を持つ製品のグルーピング
02.AIデータ分析を成功へ導く3つの実践ステップとAIの役割
本章では、AIデータ分析を成功に導くための分析過程を、3つのステップに分けて説明します。
02-1. ステップ1:分析目的の明確化とデータ準備
まずはじめに、AIを用いて「何を分析したいのか」「何を解決したいのか」「どのような成果を得たいのか」という目的 を明確化します。ここが曖昧なまま進むと、分析そのものが目的化してしまい、ビジネス価値のない結果に終わる可能性が高まります。分析目的が決まったら、目的に合ったデータの収集を行う必要があります。データが不足している場合には外部データから調達する必要も生まれます。
どのようなデータが必要かについては目的によって大きく異なるため一概には言えませんが、ここではクレジットカードの自動審査を目的とした例を挙げます。目的は「審査業務のAI移管」とします。これを実現するAIを作るために必要なデータは、審査を行うためのデータに加え、審査してOKな会員とNGな会員を区別するためのフラグです。
過去の実績から、実際に与信した 会員の申込情報 (年齢・年収・業種・役職など)と、その会員が 貸倒したかどうか を集計して1つのデータとしてまとめます。これで、与信してOKな会員とNGな会員の情報を学習させるためのデータセットがひとまず揃います。
一方で、与信するかどうかを判断するために必要な材料として、申込情報だけでは不十分ではないかという懸念点もあります。このような場合には 外部データの調達 を考えます。具体的には、信用情報機関からの外部信用情報を調達したり、法人カードならば東京商工リサーチなど企業情報を扱っている企業から財務情報・企業評価などを調達したりします。
02-2. ステップ2:AIモデルの構築と学習
次にAIモデルの選択と学習を行います。これは、データに潜むパターンをAIに学ばせる、データ分析の中核となるプロセスです。
まずは、目的に応じて最適なAIモデル(アルゴリズム)を選択します。例えば、不正利用検知なら「分類」モデル、売上予測なら「予測(回帰)」モデルといった形です。アルゴリズムには決定木、ランダムフォレスト、ディープラーニングなど様々な種類があり、データの特性や求める精度に応じて選び分ける必要があります。AIの分析根拠を解析したい場合には、説明可能性の高いXAIを実現できるモデルを用いるのも1つの選択肢です。
モデルを選択したら、早速用意したデータセットを用いて学習を行いたい所ですが、学習の前にデータセットを学習に適した形に加工する必要があります。主に行う加工は以下のものがあり、総じて特徴量エンジニアリングと呼びます。
- ・欠損値の処理
- ・学習に不要な変数の削除
- ・文字型変数の数値変換
- ・教師データの分別
- ・全体データの学習用データと評価用データへの分割
特徴量エンジニアリングが完了したら、AIモデルの学習(機械学習)を行います。機械学習の際は学習用データのみ使用し、こちらがモデルに対して行う事は基本的にはありません。AIが自動的に学習データと教師データからパターンを分析・学習していくプロセスになります。
02-3. ステップ3:AIモデルの評価と解釈
AIモデルの学習が完了したら、その性能が実用に足るものかを確認する「評価」と、AIがどのような根拠で判断しているかを理解する「解釈」を行います。
学習に使っていない未知の評価用データをモデルに推論させてみて、AIの性能として問題無いか、客観的な評価指標を用いて確かめます。次に、AIの判断根拠を可視化・解釈します。例えば、審査モデルであれば、「年収の高さが承認に強く影響している」「過去の延滞歴が否決の大きな要因になっている」といった根拠をSHAPなどの手法で明らかにします。
判断材料としては簡単なケースを挙げましたが、これによりAIの判断がビジネス上の知見と合致しているかを確認でき、人間では気づかなかった新たなインサイトを得られることもあります。
02-4. ステップ4:施策への導入と運用
モデルの有効性が確認できたら、いよいよ実際の業務へ導入し、運用していくステップに移ります。
いきなり全面的に導入するのではなく、まずは限定的な範囲でスモールスタートするのが成功の鍵 です。例えば、「このAI審査モデルを導入すると、全体の何%が自動で承認判定になるか」といったシミュレーションを行い、ビジネスへの影響を事前に予測します。
ただし、作成したモデルを初めて活用するようなプロジェクトはPoCの段階である事が多い点 と、実際に施策を行う時はシミュレーション結果よりやや精度が落ちる事も多い ため、あくまで参考値として扱う事を推奨します。
シミュレーションが完了したら、実際に自動審査を行います。シミュレーションと同じ手順で、審査用データを特徴量エンジニアリングしてAIに入力する事で自動審査が行われます。仮にAIが、人間と同水準のレベルで審査を行うことができた場合、当初の目的である「審査業務のAI移管」は達成となります。
また、モデルは一度作ったら完成!という事は無く、市場環境や顧客の行動は常に変化するため、継続的に再学習など調整を行う必要があります。毎月毎月学習を行う必要は無いですが、精度が落ちてきた場合は再度学習を行ってパフォーマンスを維持できるようにするのも大切です。
03.AIデータ分析でつまずかない!よくある落とし穴と解決策
多くの企業がAIデータ分析に期待を寄せる一方で、プロジェクトが思うように進まず、途中で頓挫してしまうケースも少なくありません。成功を阻む「落とし穴」は、ある程度パターン化されています。この章では、AIデータ分析プロジェクトで陥りがちな4つの代表的な失敗パターンと、それらを乗り越えるための具体的な解決策を解説します。
03-1. データ不足やデータ品質の問題
良いモデルを作成するためには、十分なデータ量を確保するのが重要です。しかし、ただ量を集めれば良いという訳ではありません。データの質も問題無いか確認する必要があります。よくある例としては以下の通りです。
- ・季節性を無視したデータ収集
例:売上予測なのに夏の3ヶ月分だけを収集→冬の需要が読めないモデルに。最低でも1年通したデータを収集する。 - ・学習データと本番データでカラム定義やカテゴリが違う
例:学習時では「性別:男性/女性」なのに、本番では「性別:Male/Female」になっている。AIにとっては未知の値である。必ずカラム定義は揃える。 - ・極端に少ない教師データ
例:自動審査モデルを作りたいのに、否決データが全体の1%しかなく、モデルがほぼ応諾と予測するだけになってしまう。即ち、学習データが応諾のものばかりなので「あるもの全て応諾だ」と勘違いしやすくなる状態に陥りやすい。極力、教師データの正例/負例バランスは偏りすぎないように考慮する。
【解決策】
AI導入の前に、まずは自社のデータを整備し、いつでも分析に使える状態にする「データ基盤の構築」を優先しましょう。不足しているデータは外部から購入したり、計画的に収集したりする戦略が必要です。また、データの入力ルールを定め、全社で徹底するデータガバナンスの確立も不可欠です。
03-2. AIモデルがブラックボックス化してしまう
AIとは基本的に入力から出力までの過程が見えないブラックボックスなものです。AI、特にディープラーニングのような複雑なモデルは、人間が理解できないレベルで無数の計算を行い結論を出すため、なぜその結論に至ったのかを論理的に説明することが困難だからです。
その結果、「予測精度は95%と高いが、なぜこの顧客が『解約する』と予測されたのか根拠が分からないため、具体的な対策が打てない」といった事態に陥ります。重要な経営判断や顧客への説明責任が求められる場面で、根拠の不明なAIの予測を鵜呑みにすることはできません。
【解決策】
分析の目的に応じて、解釈性の高いAIモデルを選択することが重要です。例えば、勾配ブースティングモデルはSHAPのようなXAI手法と組み合わせることで、分析根拠を事後的に解析できるため有力な選択肢の1つです。また、AIの専門家が分析結果をビジネスの視点で分かりやすく翻訳し、現場担当者との橋渡し役を担うことも解決策の1つとなります。
03-3. 社内にAIデータ分析の専門人材がいない
AIデータ分析プロジェクトを推進するには、 ビジネス知識、ITスキル、統計学の知識を併せ持つ専門人材が不可欠 です。
データサイエンティストやAIエンジニアと呼ばれるこれらの人材は、専門性が非常に高く、多くの企業で不足しているのが現状です。専門知識がないままプロジェクトを進めようとすると、適切な分析手法を選べなかったり、出てきた結果を正しく評価できなかったりと、多くの問題に直面します。
【解決策】
AIデータ分析の学習コストは非常に高いため、即座にAIデータ分析を取り入れたい場合は外部のデータ活用人材を活用するのが現実的です。加えて、データ活用人材からノウハウを吸収することで、社内のデータサイエンティストやAIエンジニアの育成も効果的に行うことが期待できます。中長期的には、社内研修やリスキリングを通じて自社の人材を育成する計画を立てることが重要になります。
弊社では、AIモデルの開発をはじめとしたデータ活用支援から内製化支援まで幅広くサポートしております。
03-4. 分析結果が施策に繋がらない(PoC止まり)
AIモデルを構築し、高い精度が出ることを確認したものの、 実際の業務改善や売上向上に繋がらず、実証実験(PoC)の段階で終わってしまう「PoC止まり」は、多くの企業が直面する課題 です。
この問題の根底にあるのは、プロジェクトの目的設定の誤りです。分析の目的を「AIモデルを作ること」自体に置いてしまうと、「モデルはできたが、これをどうビジネスに活かせばいいのかわからない」という状況に陥ります。
AIデータ分析はあくまでビジネス課題を解決するための「手段」であり、目的ではありません。
【解決策】
AIデータ分析を開始する前に目的を明確化する事が最も重要です。ゴールを「AI分析する事」にするのではなく、「AI分析して得た結果を施策に繋げる事」まで考えて分析を行いましょう。また、PoCの段階では施策をスモールスタートにして小さな成功体験を重ねながら、AI活用のスケールを広げていく事も有効です。
04.AIを使ったデータ分析に関するよくある質問(FAQ)
Q1. 自社データがない、または少ない場合でもAIデータ分析は可能ですか?
A. ゼロからのスタートは難しいですが、オープンデータや外部データとの組み合わせ、あるいは少量データからの学習(転移学習など)で始める方法もあります。ただし、精度を高めるには十分なデータ量が理想です。データ収集戦略を練り、将来を見据えて計画的にデータ収集を行う事から始めるのも立派な手段の1つです。
Q2. AIデータ分析の「精度」はどのように評価・改善すれば良いですか?
A. 精度は「ビジネス目的と紐づいた指標」で評価し、「継続的な改善サイクル」を回すことが不可欠です。 精度評価には主に2種類の指標があります。モデルとしての性能を測る評価指標(例:AUCや適合率)と、ビジネス目的と紐づいた指標(例:審査の応諾割合、否決割合)です。双方の指標の良さは比例する事が多いですが、モデル作成過程では前者を、シミュレーション時や施策結果からモデルを見る時は後者を使います。基本的には、ビジネス的に立てた目標数値をモデルが達成できなかった時に改善を検討する流れになります。改善の際には、評価指標の目標数値を達成するように調整すれば問題ありません。
まとめ
本記事では、AIデータ活用を成功させるためのAI作成ステップについて紹介しました。やや技術的な部分が多くなってしまいましたが、これからAI導入を検討している方も、一体AIはどのように作られるのか?どのようなデータが必要なのか?といった事は知っておく必要があります。
中でも「AIを用いた分析をする事」を目的にするのでは無く、「AIを用いた分析を使って何をどう成し遂げるのか」までを目的にして、入口から出口までを一気通貫で考える事が重要です。そこまで考えた上でようやく必要なAIを設計する事ができるのです。
\ データ活用についてのご相談はメンバーズデータアドベンチャーまで /
\ 相談する前に資料を見たいという方はこちら /
▶こちらも要チェック




現代ビジネスにおいて、データは企業の成長を左右する重要な資産です。しかし、日々蓄積される膨大なデータを手作業で分析するには限界があります。そこで鍵となるのが、データ分析ツールです。本記事では、「データ分析ツールって何?」「たくさんあってどれを選べばいいか分からない」といった疑問を持つ方に向けて、ツールの選び方やおすすめの種類、活用シーンを分かりやすく解説します。
▶目次
01. データ分析ツールとは?
企業が保有するデータは日々爆発的に増加し、その量は膨大になっています。こうした莫大なデータを効率的に活用するためには、手作業での集計や分析には限界があり、データに基づいた迅速かつ正確な意思決定(データドリブン)の実現を支援するのがデータ分析ツールです。
多くの企業では、デジタルトランスフォーメーション(DX)推進の一環として、データ活用の重要性が高まっています。データ分析ツールは、まさにその中核を担う存在と言えるでしょう。
1-1. データ分析ツールとは何か
データ分析ツールとは、社内に点在する膨大なデータを効率的に収集・加工・分析し、ビジネスの意思決定をデータに基づいて行うための強力なパートナーです。データベースやExcelファイル、クラウドサービスなど、様々な場所に散らばったデータを一つに集約します。
そして、専門知識がなくても直感的な操作でグラフやダッシュボード(複数のグラフや指標を一覧表示する画面)を作成し、ビジネスの現状を瞬時に「見える化」することを可能にします。これにより、勘や経験だけに頼らない、客観的な根拠に基づいた判断を下せるようになります。
単にデータを集計するだけでなく、傾向やパターンを自動的に発見したり、将来の予測を行ったりする高度な機能を持つツールも多く存在します。例えば、
- ・どの商品が、いつ、どの地域で最も売れているのか?
- ・顧客がウェブサイトでどのような行動をとっているのか?
- ・新規キャンペーンの効果はどのくらいあったのか?
といった問いに対する答えを、客観的なデータに基づいて導き出すことができます。データ分析ツールは、意思決定の迅速化と精度向上に不可欠な存在と言えるでしょう。
1-2. データ分析ツールがもたらすメリットと活用シーン
データ分析ツールを導入することで、企業は様々なメリットを享受できます。ここでは、具体的なメリットと、それに伴う活用シーンを詳しく解説します。
<データ分析の効率化と精度向上>
・分析作業の効率化と自動化
データの収集、加工、可視化といった一連のプロセスを自動化し、手作業での時間と労力を大幅に削減できます。これにより、分析担当者はより付加価値の高い、洞察を得るための「考える」時間を使えるようになります。
活用シーン:毎日作成していたExcelのレポート作成業務を自動化し、人件費を削減する。
・ヒューマンエラーの削減
自動化によって、手作業で発生しがちな入力ミスや計算ミスを防ぎ、データの正確性を飛躍的に高めます。信頼性の高いデータは、正しい経営判断の土台となります。
活用シーン:手作業による集計ミスがなくなり、会議で報告される数値の信頼性が向上する。
・分析の精度向上と深い洞察の発見
高度な統計機能やアルゴリズムを活用することで、人間だけでは見つけられないデータの傾向や相関関係、異常値などを発見し、より深い洞察を得られます。
活用シーン:これまで気づかなかった「特定の商品Aと商品Bを一緒に購入する顧客層」を発見し、新たなセット販売戦略を立案する。
<客観的なデータに基づいた迅速な意思決定>
・現状の「見える化」による共通認識の醸成
リアルタイムで更新されるグラフやダッシュボードを通じて、ビジネスの現状を関係者全員が客観的に、そして共通の認識で把握できます。
活用シーン:全部門のKPIをダッシュボードで共有し、全社的な目標達成に向けた一体感を醸成する。
・迅速な意思決定
データに基づいた正確な情報が瞬時に手に入るため、勘や経験に頼ることなく、スピーディーかつ根拠のある経営判断が可能になります。
活用シーン:売上速報をリアルタイムで確認し、販売不振の兆候があれば即座に対策会議を開く。
・ビジネスチャンスの獲得
市場や顧客の動向をリアルタイムで追跡することで、変化の兆候をいち早く察知し、競合他社に先んじて新たなビジネスチャンスを掴むことができます。
活用シーン:SNSのトレンドデータを分析し、次に流行しそうな商品をいち早く仕入れて販売する。
<新たなビジネス機会の発見>
・潜在ニーズの発見
顧客の購買履歴や行動データを分析することで、これまで気づかなかった顧客ニーズや、隠れた市場トレンドを発見できます。
活用シーン:ある商品の意外な使われ方を顧客レビューから発見し、新たなターゲット層へのプロモーションを展開する。
・未来の予測
過去のデータを基に需要や市場の変動を予測し、新商品の開発や在庫管理の最適化に役立てられます。
活用シーン:過去の気象データと売上データを分析し、気温に応じた最適な在庫量を予測して廃棄ロスを削減する。
<業務プロセスの改善>
・マーケティング活動の最適化
広告キャンペーンの効果をリアルタイムで分析し、費用対効果の高いチャネルにリソースを集中させることができます。
活用シーン:複数のWeb広告の効果をダッシュ-ボードで比較し、最もコンバージョン率の高い広告に予算を重点的に配分する。
・営業活動の効率化
顧客データを分析することで、成約率の高い見込み客を特定し、営業担当者が効率的にアプローチできるよう支援します。
活用シーン:過去の受注実績から「優良顧客」になりやすい企業のパターンを分析し、アプローチリストの優先順位付けを行う。
・生産・在庫管理の高度化
生産ラインのデータを分析し、非効率なプロセスやボトルネックを特定して改善に繋げられます。また、需要予測によって適切な在庫レベルを維持し、過剰在庫や欠品を防ぎます。
活用シーン:工場のセンサーデータを分析して設備の故障時期を予測し、計画的なメンテナンスを行うことで生産停止のリスクを最小化する。
02. 【目的別】おすすめデータ分析ツールの種類と特徴
データ分析ツールは、その目的や得意分野によっていくつかのカテゴリに分類できます。ここでは、代表的な4つのカテゴリに分けて、それぞれのおすすめツールとその特徴を解説します。
2-1. 可視化・BIに強みを持つツール
ビジネスインテリジェンス(BI)ツールは、複雑なデータを直感的なグラフやダッシュボードで表現し、ビジネスの状況を「見える化」することに特化したツール群です。専門的な知識がなくても、視覚的にデータを分析できる点が最大の強みです。
<Tableau>
出典:「Tableau | BI と分析のためのソフトウェア」
データの可視化において世界的に高い評価を得ているBIツールです。直感的なドラッグ&ドロップ操作で、多様なグラフやインタラクティブ(操作可能)なダッシュボードを簡単に作成できます。デザイン性に優れており、プレゼンテーション資料としても映える、美しく分かりやすいレポートを作成したい場合に特に適しています。


<Microsoft Power BI >
出典:「Power BI - データの視覚化 | Microsoft Power Platform」
Microsoftが提供するBIツールで、ExcelやOffice 365など、既存のMicrosoft製品との連携に優れています。使い慣れたExcelのような操作感で始められるため、導入のハードルが低いのが特徴です。無料版から始めることができ、クラウドサービスとの連携機能も充実しているため、組織全体でのデータ共有をスムーズに行うことができます。

<Looker Studio(旧Google データポータル)>
出典:「Looker Studio」
Googleが提供する無料のBIツールです。Google AnalyticsやGoogle BigQuery、Google広告といったGoogle製品との連携が非常に強力で、数クリックでデータを接続できます。Webサイトのトラフィック分析やマーケティングデータの可視化に特に適しており、直感的な操作でレポートを作成できるため、Web担当者やマーケターに人気のツールです。
<Domo>
出典:「Domo」
クラウドベースのBIプラットフォームで、データ統合から可視化、共有までをワンストップで提供します。様々なシステムとのデータ連携コネクタが豊富に用意されており、社内に散らばったデータのサイロ化(孤立化)を解消するのに役立っています。モバイルからの利用に強みがあり、スマートフォンやタブレットで、いつでもどこでもビジネスの状況をリアルタイムに把握できる点が特徴です。
2-2. 統計解析・予測に強みを持つツール
統計解析ツールは、複雑な統計モデルの構築や高度な予測分析、多変量解析など、データからより深い洞察を得ることに特化しています。専門的な分析を通じて、ビジネス上の課題に対する科学的な根拠を得たい場合に利用されます。
<Exploratory>
出典:「Exploratory」
プログラミング言語であるRの高度な統計機能を、GUI(グラフィカルユーザーインターフェース)上で直感的に操作できるツールです。プログラミングの知識がなくても、統計解析、機械学習、データ可視化などを一貫して行えます。データサイエンティストだけでなく、ビジネスアナリストでも高度な分析を実行できる点が強みです。
<SPSS>
出典:「IBM SPSSソフトウェア」
IBMが提供する歴史ある統計解析ソフトウェアです。社会調査やマーケティングリサーチなど、特に学術分野や市場調査で広く利用されてきました。高度な統計解析機能を豊富に備えており、多様な統計モデルを構築できます。長年の実績があり、使い慣れたユーザーにとっては、複雑な分析も効率的に行える点が大きなメリットです。
<JMP>

出典:「動的なデータ探索のための統計ソフトウェア」
SAS社が提供する統計解析ソフトウェアです。データの探索的な分析に強みを持ち、マウス操作で簡単にグラフを作成したり、統計解析を実行したりできます。特に製造業や研究開発分野で品質管理や実験計画法に活用されており、視覚的にデータを深く掘り下げたい場合に適しています。
2-3. AI・機械学習に強みを持つツール
AI・機械学習ツールは、高度な予測モデルや分類モデルの構築・運用を効率化することに特化しています。専門的な知識がなくてもAIをビジネスに活用できる機能を提供しているのが特徴で、需要予測や顧客の離反予測などに利用されます。
<DataRobot>

出典:「DataRobot」
AI・機械学習を自動化するAutoML(Automated Machine Learning)プラットフォームの代表格です。プログラミングの知識がなくても、高精度な予測モデルを短時間で作成できます。多様なアルゴリズムを自動で比較し、最適なモデルを提案してくれるため、AI活用の専門家がいない企業でも精度の高いモデルを開発できます。
<Amazon SageMaker>
出典:「すべてのデータ、分析、AI のセンター – Amazon SageMaker」
Amazon Web Services (AWS)が提供する包括的な機械学習サービスです。データの前処理からモデルの構築、トレーニング、デプロイまで、機械学習のワークフロー全体をサポートします。多くのAIモデルやフレームワークに対応しており、データサイエンティストが自由にカスタマイズして、高度なAIモデルを構築・運用するのに適しています。
<Google Cloud Vertex AI>
Google Cloudが提供する統合型機械学習プラットフォームです。AIモデルの構築やデプロイ、管理までを統合された環境で行えます。Googleの持つ豊富なAI技術を活用でき、特にGoogle Cloud上でデータ分析やAI開発を行っている企業に適しています。
2-4. その他の専門分野に特化したツール
BIツールや統計解析ツールに加え、特定の専門分野に特化したデータ分析ツールも数多く存在します。それぞれが特定の用途に最適化されており、専門的な分析を効率的に行うことができます。
<Google Analytics>
出典:「Google Analytics | Google for Developers」
Webサイトやアプリのアクセス解析に特化したツールです。ユーザーの流入経路、サイト内での行動、コンバージョン率などを詳細に分析でき、Webマーケティングの改善に不可欠な情報を提供します。無料から利用できるため、多くの企業で導入されています。
<Adobe Analytics >
出典:「Adobe Analytics | web、製品、モバイル分析ソリューション | アドビ」
Adobeが提供する高機能なWeb解析ツールで、Google Analyticsよりもさらに高度で詳細なデータ分析が可能です。特に、膨大なデータを保有する大企業や、複数のプラットフォームを横断した分析を行いたい場合に強みを発揮します。
<CRMに搭載された分析機能>
SalesforceやHubSpotなどの顧客関係管理(CRM)ツールには、顧客データ分析機能が搭載されていることが一般的です。顧客の購買履歴、問い合わせ履歴、行動データなどを一元管理し、顧客セグメンテーションや、個別のニーズに合わせた営業・マーケティング戦略を立てるのに役立ちます。
<マーケティングオートメーション(MA)ツール>
MAツールは、マーケティング活動の自動化だけでなく、顧客の行動データ(メールの開封率、ウェブサイトの閲覧履歴など)を自動で収集・分析します。これにより、個々の顧客に最適化されたコミュニケーションを可能にし、リード(見込み客)の育成や顧客ロイヤルティの向上に貢献します。
03. データ分析ツールの選び方:自社に最適なツールを見つけるポイント
数多くのデータ分析ツールの中から自社に最適なものを選ぶためには、いくつかの重要なポイントがあります。ここでは、ツール選定で失敗しないための5つの具体的なポイントを解説します。
3-1. 目的と課題の明確化
数多くあるデータ分析ツールの中から、自社に最適なツールを選ぶための最初の、そして最も重要なステップは、「何のためにデータ分析ツールを導入するのか」という目的と課題を明確にすることです。
目的が定まっていなければ、ツールの機能ばかりに目が行き、最終的に「導入したけれど、使い道がない」という事態に陥りかねません。例えば、
- ・「日々の売上をリアルタイムで把握したい」
- ・「顧客行動を分析して新商品を開発したい」
- ・「製造ラインの不良品発生率を予測したい」
など、解決したい課題を具体的に設定しましょう。この目的によって、選ぶべきツールの種類は大きく変わります。シンプルな可視化ツールで十分な場合もあれば、高度な統計解析やAI機能を持つツールが必要になる場合もあります。目的を具体化することで、必要な機能や予算の範囲が定まり、ツールの選定プロセスが大きく効率化されます。
3-2. 操作性と使いやすさ
データ分析ツールの選定において、操作性と使いやすさは非常に重要なポイントです。どんなに高機能なツールでも、現場の担当者が使いこなせなければ意味がありません。
特にデータ分析の専門家ではないユーザーが使うことを想定する場合、
- ・直感的なUI(ユーザーインターフェース)であるか
- ・ドラッグ&ドロップで簡単にグラフを作成できるか
- ・複雑なコーディング知識を必要としないか
- ・データの可視化をスムーズに行えるか
いった点をチェックしましょう。ツールによっては、習得に時間とコストがかかり、定着しないリスクがあります。無料トライアル期間を利用したり、デモ版を試したりして、実際にチームメンバーが触れてみることをおすすめします。現場の担当者が「これなら使えそうだ」と思えるツールを選ぶことが、導入後のスムーズな活用に繋がります。
3-3. 分析機能とデータ連携能力
データ分析ツールを選ぶ際は、必要な分析機能とデータ連携能力をしっかり見極めることが重要です。ツールの機能が目的と合致しているか、また、既存のデータソースとスムーズに連携できるかが、その後の運用を大きく左右します。
まず、自社でどのような分析が必要かを確認しましょう。単にデータを可視化したいのであれば、BIツールが適しています。より深い洞察を得るために統計解析や予測分析が必要であれば、それらに特化したツールを選びます。
次に、データ連携能力も重要なポイントです。多くの企業データは、Excelファイル、各種データベース、SaaSアプリケーションなど、さまざまな場所に分散しています。選定するツールがこれらの多様なデータソースと簡単に接続し、自動でデータを更新できるかを確認してください。API連携やクラウドサービスとの接続性に優れているツールは、日々のデータ収集の手間を大幅に削減し、効率的な分析環境を構築できます。
3-4. コストと費用対効果
データ分析ツールの導入を検討する際、コストと費用対効果を正確に評価することも不可欠です。ツールの価格体系は、買い切り型、月額・年額のサブスクリプション型、利用量に応じた従量課金制など、多岐にわたります。まずは、初期費用だけでなく、ライセンス費用、メンテナンス費用、トレーニング費用など、導入後にかかるランニングコストも含めた全体像を把握しましょう。
重要なのは、単にツールの価格が安いか高いかではなく、そのコストに見合う効果が得られるかという視点です。例えば、高機能で高価なツールでも、それによって業務効率が大幅に向上したり、新たなビジネス機会が創出されたりすれば、長期的に見て高い費用対効果が得られます。逆に、安価なツールを選んでも、目的の分析ができず、追加の費用や時間が発生する可能性もあります。期待される効果(業務効率化による人件費削減、売上向上など)を具体的に試算し、コストとのバランスを慎重に検討しましょう。
3-5. サポート体制とコミュニティの充実度
データ分析ツールを選ぶ上で、サポート体制とコミュニティの充実度も重要な判断基準です。ツールの導入はゴールではなく、その後の運用が成功の鍵を握ります。導入時や運用中に予期せぬ問題が発生した際、ベンダーからのサポートが迅速かつ的確であるかは非常に重要です。特に社内に専門家がいない場合、電話やメールでのサポート、日本語対応の有無などを事前に確認しておきましょう。
また、活発なユーザーコミュニティや豊富な学習リソース(チュートリアル、ドキュメント、ウェビナーなど)があるかどうかもチェックポイントです。コミュニティが活発であれば、他のユーザーが直面した課題の解決策を見つけやすくなり、自社のノウハウとして蓄積できます。さらに、質の高い学習リソースは、社員のスキルアップを促し、ツール活用の内製化を加速させます。
ツールの機能やコストだけでなく、導入後の運用を支えるこれらの要素を総合的に評価することが、最適なツール選定に繋がります。
04. データ分析ツールに関するよくある質問(FAQ)
Q1. 自社に分析の専門家がいなくても、データ分析ツールは使えますか?
・A. はい、使えます。近年は専門家でなくても直感的な操作で扱えるツールが増えており、基本的なデータの可視化や分析は可能です。まずは本記事で紹介したような無料プランのあるBIツールから始め、データに触れる文化を醸成することをおすすめします。
ただし、より高度な分析(統計モデリング、機械学習など)や、ツール導入の戦略設計には専門知識が有効です。その際は、社内での人材育成と並行して、必要な時に外部の専門家の支援を受けるといった選択肢も視野に入れると、データ活用をスムーズに加速させることができます。
Q2. 導入コストに見合う効果が得られるか不安です。
・A. ツール導入にはコストがかかりますが、データに基づいた意思決定による業務効率化、売上向上、新たなビジネス機会創出など、中長期的なリターンが期待できます。具体的なROI(投資収益率)は目的やデータの質によって異なりますが、特定の課題に絞ったスモールスタートで効果を検証し、段階的に投資を拡大することをおすすめします。
Q3. どのツールを選べば良いか迷っています。客観的なアドバイスが欲しいのですが?
・A. 数多くのツールがある中で、自社の目的やデータの状況に最適なツールを選ぶのは容易ではありません。ツールの機能や費用だけでなく、導入後の運用までを見据えた選定が重要です。
まずは複数のツールベンダーから話を聞き、デモンストレーションを依頼することをおすすめします。その上で、データ分析の専門家による客観的なアドバイスや、第三者視点での比較検討(ITコンサルタントへの相談など)が有効な場合も多々あります。自社だけで抱え込まず、外部の知見を活用することも検討しましょう。
まとめ
本記事では、データ分析ツールがもたらすメリットや目的別のおすすめツール、そして自社に最適なツールを選ぶためのポイントを網羅的に解説しました。現代のビジネスにおいて、データは企業の成長を左右する極めて重要な資産です。
データ分析ツールは、膨大なデータを効率的に分析・可視化し、データドリブンな意思決定を支援する強力なツールです。
可視化・BI、統計解析・予測、AI・機械学習など、目的に応じて選ぶべきツールの種類は異なります。
ツール選びでは、目的の明確化、操作性、機能・連携能力、コスト、そしてサポート体制を総合的に評価することが成功の鍵となります。
データ分析ツールの導入は、単なるツールの購入で終わりではありません。それは、社内に眠るデータの力を最大限に引き出し、ビジネスの成長を加速させるための重要な第一歩です。
\ データ活用についてのご相談はメンバーズデータアドベンチャーまで /
\ 相談する前に資料を見たいという方はこちら /
▶こちらも要チェック
2025年9月17日(水)に実施された英明フロンティア高等学校のデータサイエンティスト体験授業にて、弊社の佐藤舞奈が講師として参加しました。
本授業へは、弊社が賛助会員を務めている一般社団法人データサイエンティスト協会の活動の一環として参加しました。
佐藤より自身のデータ活用業務についての紹介や、生徒さんからの進路に関する質問などに答えました。
開催レポートはこちら
【イベントレポート】『データサイエンティスト』を体験する濃い1日! 英明フロンティア高校1年生へのDS体験授業レポート(2025年9月17日)(データサイエンティスト協会 DSSジャーナル)
メンバーズデータアドベンチャーカンパニーでは、このような講義でのゲストスピーカーの派遣も行っております。
下記問い合わせフォームよりお気軽にお問い合わせください。
企業の成長や競争力強化には、社内に眠る膨大なデータの活用が不可欠です。営業や人事、製造など各部門で蓄積されるデータを効果的に分析・活用することで、業務効率化や新たな価値創出が可能になります。
「社内に蓄積されたデータをどう活かせば良いかわからない」「データ活用と言われても、何から手をつければいいのか…」このようなお悩みをお持ちではないでしょうか。
本記事では以下の内容をお伝えします。
- ・社内データ活用とは何か、その重要性ともたらすメリット
- ・営業・人事・製造など部署ごとの具体的な活用事例
- ・社内データ活用を成功させるステップと課題解決のヒント
▶目次
01.企業成長の鍵「社内データ活用」とは?その重要性とメリット
01-1.社内データ活用とは?
社内データ活用とは、企業内で日々蓄積されるさまざまなデータを収集、整理、分析することで、業務改善やビジネス上の意思決定、新たな価値創造などに役立つ情報として有効活用する一連の取り組みを指します。企業では営業記録、顧客情報、人事データ、生産実績、在庫データなど、企業活動のあらゆる場面でデータが生成され続けています。しかし、それらが部門ごとに散在し、ただ蓄積されるだけでは、組織全体の成長や効率化に直結しません。
そのため、単に数値や履歴を管理するだけでなく、これらのデータを整理・統合し、分析や可視化を行うことで、業務改善や経営判断、さらにはビジネスの発展に活かすことが重要となります。
01-2.社内データ活用がもたらすメリット
社内データ活用は、企業に多様な恩恵をもたらします。中でも特に重要なのが、以下の3つのメリットです。
- ・意思決定のスピード・精度向上
直感や経験だけに頼らず、社内でデータに基づいた迅速かつ的確な意思決定が可能になります。 - ・業務効率化やコスト削減
業務フローの無駄やボトルネックをデータから把握し、改善施策を講じることで、業務プロセスの最適化とコスト削減を実現します。 - ・新たな価値創出・競争力強化
顧客行動や市場データを分析し、潜在ニーズやトレンドを先取りすることで、迅速な戦略立案が可能となり、市場での優位性を高めます。
02.部署別データ活用実践例:眠れるデータを価値に変えるアプローチ
社内データ活用は、特定の部門だけのものではありません。この章では、各部門が保有するデータをどのようにビジネスの価値へと転換できるのか、具体的な実践例を交えながらご紹介します。
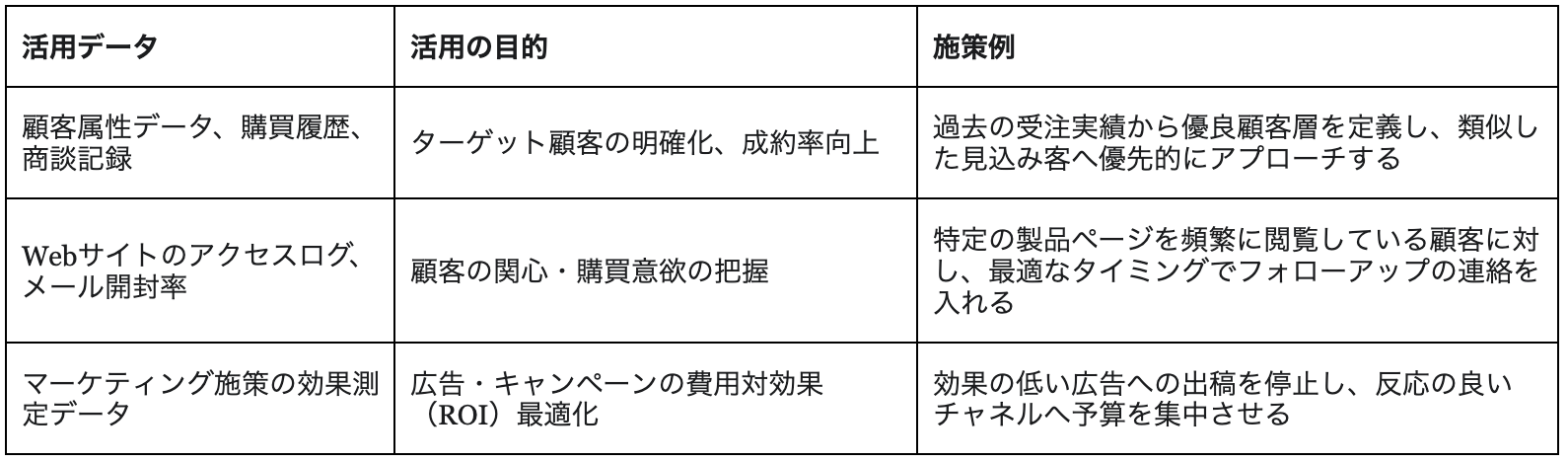
02-1.営業・マーケティング部門におけるデータ活用
営業・マーケティング部門では、顧客属性や購買履歴、商談記録、Webサイトのアクセスログ、SNSの反応など多種多様なデータが日々蓄積されています。これらを活用することで、成約率の高い顧客層を抽出し、最適なタイミングやチャネルでアプローチできます。さらに、広告やキャンペーン施策の効果をデータで可視化することで、投資対効果を分析し、効果的な施策にリソースを集中することが可能です。その結果、営業活動の効率化、マーケティングコストの最適化、顧客満足度の向上などの成果が期待できます。
02-2.人事部門におけるデータ活用
人事部門では、勤怠記録や評価データ、スキル情報、採用履歴などの人材データが存在しています。これらのデータを蓄積し、分析することで、離職リスクの早期察知や職場環境の改善が可能です。さらに、スキル可視化による人材配置の最適化や教育プランの設計、採用データ分析による求人の最適化にも活かせます。これらの活用は、従業員エンゲージメントと組織全体の生産性向上につながります。

02-3.製造・生産管理部門におけるデータ活用
製造・生産管理部門では、設備稼働データや品質検査結果、在庫状況、生産実績など膨大なデータが生成されます。これらを活用することで、生産ラインのボトルネック特定や効率的な工程改善が可能です。また、センサー情報などを活かして異常を早期に発見し、計画的な設備保全を行えるほか、在庫データや出荷データを組み合わせて需要予測や在庫最適化を実現し、品質向上やコスト削減にもつながります。

02-4.経理・財務部門におけるデータ活用
経理・財務部門では、財務諸表や取引履歴、支出・収益データ、キャッシュフローなどのデータが日々蓄積されています。これらを活用することで、コスト分析や利益率の可視化による経営の効率化、過去データを基にした収益予測による戦略精度の向上などが可能になります。また、不正検知やリスク分析を通じてガバナンス強化にもつながります。

02-5.その他の部署におけるデータ活用の可能性
広報、総務、ITなど、あらゆる部署でデータ活用の可能性が広がっています。広報ではWeb解析やSNSデータを基に情報発信やブランド戦略を最適化、総務ではアンケートや問い合わせ履歴を分析して社員満足度向上などに活かすことが可能です。IT部門ではシステムログや行動データを活用し、データドリブンな運用改善やセキュリティ強化を推進できます。

このようにデータは部門を問わず価値を生む資産であり、全社的な活用が競争力強化の基盤となります。
03.社内データ活用を成功させるためのステップとポイント
データ活用の重要性を理解しても、何から手をつければよいか分からないという方も多いでしょう。この章では、社内データ活用を成功に導くための具体的な5つのステップと、重要なポイントを解説します。
ステップ1:目的の明確化とKPI設定
データ活用を進める上で最初に重要となるのは、「何のためにデータを活用するのか」という目的を明確にすることです。目的が曖昧なままでは、分析や施策が場当たり的になり、成果に結びつきません。
まずは「営業部門の新規顧客獲得数を前年比10%向上させる」といった、具体的で測定可能なビジネス上の目標(KGI)を設定しましょう。そして、そのKGIを達成するための中間指標としてKPI(重要業績評価指標)を定めることで、取り組むべき課題が具体的になります。
ステップ2:現状データの把握と課題特定
目的が定まったら、まずは社内にどのようなデータが存在するのかを把握することが重要です。データの種類・量・品質・所在を洗い出し、全体像を明確にします。そのうえで、データが有効活用できていない原因を特定することが次のステップにつながります。部門ごとのデータサイロ化や、入力ミス・重複データなど品質の問題が活用の障壁となっているケースは少なくありません。自社のデータを客観的に評価し、理想と現状のギャップを正確に把握することで、データ基盤の整備や改善の優先度を正しく判断できます。
ステップ3:データ収集・統合・整備の実行
課題を把握したら、次は社内に散在しているデータを収集・統合し、分析できる形に整備するステップです。各部署のシステムやExcelファイルなど、社内外に散在するデータを抽出・統合し、ETLやデータパイプラインを活用します。重複や欠損を修正するデータクレンジングを行い、加工・構造化することで、信頼性の高いデータ基盤を構築し、次の分析工程へ進めます。また、データの所在や定義を可視化し、分析に必要な情報を効率的に把握する仕組みとしてデータカタログを活用すると、整備作業がスムーズになります。
ステップ4:分析と示唆の抽出
整備されたデータを基に、いよいよ分析を行い、ビジネスに役立つ「示唆(インサイト)」を抽出するステップです。整備したデータは、BIツールや機械学習を用いて可視化や予測・分析などを実施することで、具体的なインサイトを導き出します。分析結果はグラフやダッシュボードで分かりやすく可視化します。このときデータという客観的な事実(ファクト)から、「なぜこのような結果になったのか」「次に何をすべきか」といった解釈や仮説を導き出すことが重要です。
ステップ5:施策実行と効果測定、改善
分析結果は、業務や戦略に反映して初めて価値を生みます。このステップでは、分析結果を基に営業戦略の変更やマーケティング施策の実行など、具体的なアクションプランを立てて実行します。
営業戦略の見直しやマーケティング施策の最適化など具体策を迅速に実行し、KPIで成果を測定・検証します。PDCAを繰り返すことが精度と効果の向上に繋がり、データ活用を組織に根付かせる鍵となります。
成功のポイント:スモールスタートで小さな成功体験を積み重ねる
社内データ活用の成功には、経営層のコミットメントと全社的な推進が不可欠です。データに基づく意思決定の文化を育むため、まずは特定部署で小規模プロジェクトを実施し、成果を可視化・共有します。小さな成功体験を積み重ねることで社内の理解と協力を得やすくなり、全社横断でのデータ活用へ展開できます。
04.社内データ活用におけるよくある課題と解決策
社内データ活用の道のりは、常に平坦とは限りません。この章では、データ活用を阻む4つのよくある課題を取り上げ、それぞれの具体的な解決策を提示します。
課題1:データが散在し、必要なデータが見つからない
多くの企業では、各部署が独自のシステムやファイル形式でデータを管理しているため、組織全体で見るとデータがバラバラに散在している「データのサイロ化」が起きています。この状態では、分析に必要なデータを集めるだけで多大な時間と労力がかかり、迅速な意思決定の妨げとなりかねません。
この課題の解決にはデータレイクやDWH(データウェアハウス)などの統合基盤を構築し、データを一元管理できる仕組みを整えることが有効です。さらに、データカタログを導入することで、データの所在や定義を可視化し、必要なデータを迅速に検索・利用できるようになります。
課題2:データの品質が悪く分析に使えない
「入力ミス」「表記の揺れ」「データの欠損」といった問題は、分析結果の信頼性を著しく損ない、誤った経営判断を導くリスクさえあります。
このような事態を防ぐにはデータクレンジングや正規化などの整備プロセスを定期的に実施し、常に分析可能な状態を維持することが重要です。さらに、データ入力ルールの策定や、各部門でのデータガバナンス強化も重要となります。データカタログを活用すれば、データ定義や品質指標を登録、注意点などをメタデータとして登録することもでき、品質維持が容易になります。
課題3:データを活用できる人材がいない・育たない
データ活用を推進するには、ツールの導入だけでなく、それを使いこなす人材が不可欠です。しかし、多くの企業では「データを扱える専門人材がいない」「従業員全体のデータリテラシーが低い」といった人材面の課題を抱えています。
この課題を解決するには、社内研修やワークショップでデータリテラシーを向上させ、実践的な学習機会を提供します。さらに、データ活用に特化した人材の外部専門家や常駐サービスや外部リソースを活用することで、内製化と並行しながらプロジェクトを着実に進められます。
課題4:データ活用に対する社内の理解が得られない
データ活用は、一部の部署だけで進めても大きな成果にはつながりません。しかし、現場の従業員や経営層から「なぜデータ活用が必要なのか」といった抵抗にあい、推進が滞るケースは少なくないでしょう。
この壁を乗り越えるには小規模プロジェクトで成功事例をつくり、成果を可視化・共有することで社内の理解を促すことが有効です。さらに、経営層がデータ活用の重要性を発信し、勉強会や研修などを通じて社員全体のデータリテラシーを底上げすることで、社内の意識統一を図れます。
05.社内データ活用に関するよくある質問(FAQ)
Q1. 社内データ活用は中小企業でも可能ですか?
A. 規模に関わらずデータは重要な資産であり、中小企業でも可能です。スモールスタートで特定の業務から始めるなど、自社の状況に合わせたアプローチが有効です。
Q2. データ活用ツールを導入すればデータ活用が進みますか?
A. ツールはあくまで手段であり、それだけでは進みません。明確な目的、適切な人材、データ品質の確保、運用体制など、総合的な取り組みが不可欠です。また、分析結果を業務に反映する仕組みや、現場での定着を支える教育・運用ルールの整備が成功の鍵となります。
Q3. どのようなデータが社内データ活用に適していますか?
A. 顧客データ、営業履歴、生産データ、勤怠データ、Webアクセスログなど、あらゆるデータが対象になり得ます。特に、具体的なビジネス課題の解決に役立つデータから着手するのが効果的です。
Q4. データ活用人材の育成には何が必要ですか?
A. データリテラシー研修、BIツールの操作スキル習得、データ分析の考え方(仮説検証)の教育が必要です。実践的な経験を積む場を提供したり、外部の専門家からのサポートを受けたりすることも有効ですし、常駐サービスでノウハウを定着させることも可能です。
Q5. データ活用の効果はいつ頃から現れますか?
A. 取り組みの規模によりますが、特定の課題に絞ったスモールスタートであれば数ヶ月で効果を実感できることもあります。全社的なデータドリブン経営の定着には、継続的な取り組みと時間が必要です。効果を早期に実感するには、取り組み前にKPIを設定し、定期的に効果測定と改善を繰り返すことが重要です。
まとめ
社内データの活用は、企業成長や競争力強化に不可欠な取り組みです。本記事では、社内データ活用の定義とメリット、営業・人事・製造・経理などの部署ごとの具体的な事例、そして活用のためのステップを解説しました。データを資産として活用するためには、目的の明確化、現状データの整理・統合、分析による示唆の抽出、そして施策の実行と改善が欠かせません。さらに、データ品質の向上や人材育成、組織文化の醸成といった課題への対応も重要です。まずはスモールスタートで小さな成功体験を積み重ね、全社的なデータドリブン経営へとつなげていくことが、データ活用を持続的に成長の原動力へ変える鍵となります。
弊社データアドベチャーカンパニーではデータのプロ常駐サービスを提供し、企業のデータ活用内製化をご支援しております。
\ データ活用についてのご相談はメンバーズデータアドベンチャーまで /
\ 相談する前に資料を見たいという方はこちら /
▶こちらも要チェック
IT導入による業務改善を進める中で、それが本当にデジタルトランスフォーメーション(DX)につながっているのか疑問を感じていませんか?本記事では、IT化とDXの本質的な違いを明確にし、企業競争力を高める上でDXがいかに不可欠であるかを詳しく解説します。2025年の崖を乗り越え、自社に必要な変革を見出す手助けとなれば幸いです。
▶目次
01. DXとIT化、根本的な違い
DX(デジタルトランスフォーメーション)とIT化は、しばしば混同されがちですが、その目的と範囲において根本的な違いがあります。この章では、それぞれの定義を明確にし、両者の関係性を解き明かしていきます。
01-1. IT化とは?業務効率化・コスト削減の手段
IT化とは、情報技術(Information Technology)を導入し、既存業務のデジタル化やシステム導入を通じて、業務プロセスを効率化し、コストを削減することを指します。その主な目的は、「現状の改善」、「業務の効率化」、そして「コストの削減」にあります。
アナログな手作業や紙媒体での業務をデジタルに置き換えることで、作業時間や人的ミスを減らし、業務の正確性とスピードを高めます。具体的には、会計ソフトの導入による経理業務の自動化や、Web会議システムの活用による移動コスト削減、紙媒体資料の電子化などがIT化にあたります。つまりIT化は、現状の業務をデジタル技術で「置き換える」ことで、限定的な範囲の課題解決を図るための手段といえるでしょう。
01-2. DXとは?ビジネスモデル・企業文化の変革
DX(デジタルトランスフォーメーション)とは、デジタル技術を駆使して、顧客体験、提供する製品・サービス、ビジネスモデル、さらには企業や組織の文化そのものを根本的に変革することを意味します。これは単なる業務効率化にとどまらず、その究極的な目的は「競争優位性の確立」や「新たな価値創造」にあります。例えば、製造業がIoTで収集したデータをもとに故障予知サービスを始めたり、小売業がAIによる需要予測で在庫を最適化したりする取り組みがDXに該当します。DXの本質は、デジタルを前提としてビジネスのあり方を根本から「再定義」し、企業全体の競争力を高める点にあります。
01-3. IT化はDXの「手段」、DXは「目的」
このように、IT化とDXは異なる概念でありながら密接に関連しています。IT化はDXを実現するための一つの重要なステップであり、DXはIT化を通じて達成されるべき「目的」であると言えます。例えば、サブスクリプション型のビジネスモデルへ転換する(DX)ためには、まず顧客管理や課金システムを導入する(IT化)必要があります。重要なのは、IT化をゴールとせず、それによって得られたデータや効率化されたリソースを、いかにして新たな顧客価値や競争力向上という「目的」につなげるかという視点です。
02. IT化の限界とDXの必要性
IT化が進む一方で、現代の市場環境においては、IT化だけでは対応しきれない課題も顕在化しています。
02-1. 市場変化への対応と競争力維持
現代のビジネス環境は、デジタル技術の進化や顧客ニーズの多様化によって急速に変化しています。IT化は既存業務の効率化には貢献するものの、それだけでは根本的な企業競争力の強化にはつながりにくいという限界があります。企業が市場の変化に柔軟に対応し、競争力を維持・向上させるためには、IT化を超えたDXの視点が必要不可欠です。
02-2. 経産省が指摘する「2025年の崖」問題
日本企業がDXを推進すべき大きな理由の一つに、経済産業省が2018年の「DXレポート」で警鐘を鳴らした「2025年の崖」問題が挙げられます。これは、老朽化した基幹システム(レガシーシステム)が、データ活用の阻害や国際競争力の低下を招くリスクを指すものです。
このまま課題を放置すれば、日本経済に深刻な影響が及ぶ可能性があります。レポートでは、もし企業が課題を克服できなければ、2025年以降、年間で最大12兆円の経済損失が生じるかもしれないと試算されています。この「2025年の崖」を乗り越えるためにも、既存システムを刷新し、DXを推進することが喫緊の課題なのです。
参照:「DXレポート ~ITシステム「2025年の崖」克服とDXの本格的な展開~」(経済産業省)https://www.meti.go.jp/policy/it_policy/dx/20180907_02.pdf(2025年8月18日に利用)
02-3. データ活用による新たな価値創造の必要性
IT化によって収集されたデータは、単に保存されているだけではその価値を最大限に発揮できません。DXにおいては、IT化で集積されたデータを分析・活用し、それに基づいて新サービスの開発や顧客体験の向上といった、新たなビジネス価値を生み出すことが極めて重要となります。
例えば、動画配信サービスは膨大な視聴履歴データを分析し、視聴者が求めるコンテンツを高い精度で制作することで大ヒット作を生み出しています。IT化で蓄積されたデータをDXで活用し、顧客理解の深化や新サービスの開発につなげることが、新たな価値創造の鍵を握ります。
03. DXとIT化、それぞれの目的と具体的な取り組み
IT化とDXは、その目的や具体的な取り組みにおいて大きく異なります。自社の課題や目指すべき方向性を見極めるために、両者の違いを正しく理解することが重要です。
03-1. IT化の目的と取り組み例
IT化の主な目的は、業務効率化、コスト削減、そして情報共有の円滑化です。具体的な取り組み例としては、以下が挙げられます。

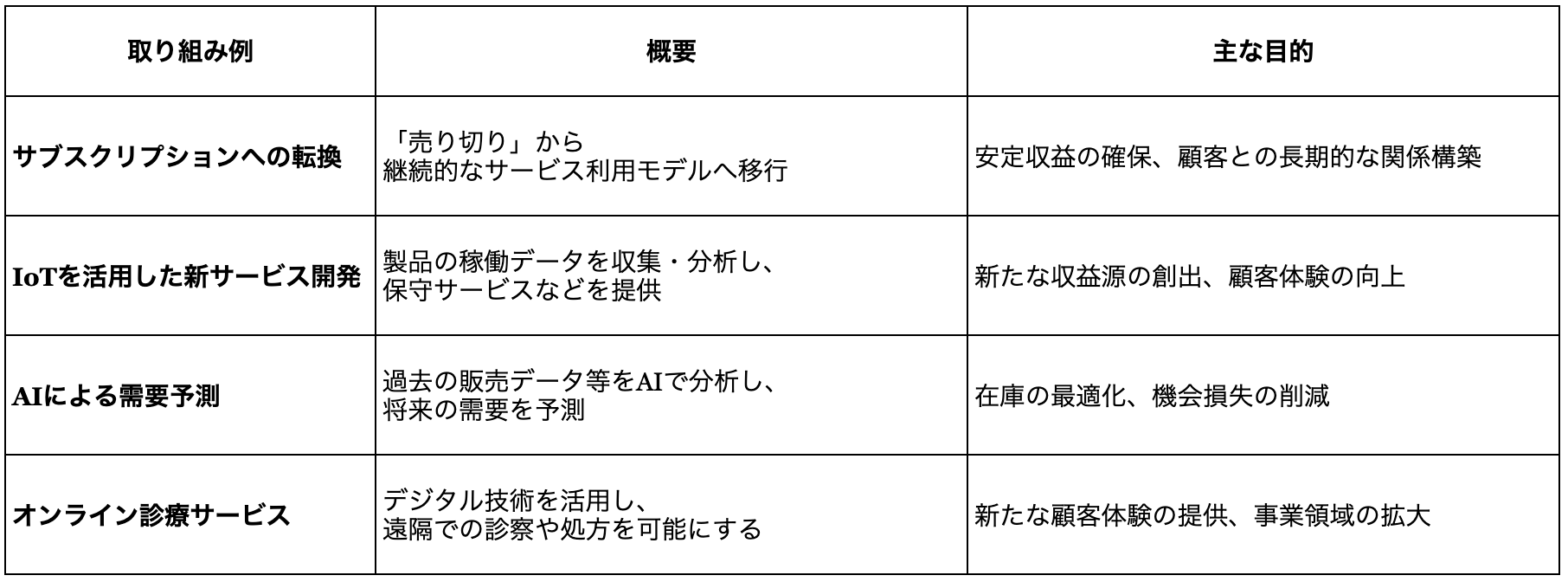
03-2. DXの目的と取り組み例
DXの目的は、ビジネスモデルの変革、新たな顧客体験の創出、競争優位性の確立、そして企業文化の変革といった、より本質的で広範なものです。具体的な取り組み例は以下の通りです。
03-3. 自社に必要なのはIT化?それともDX?判断基準
自社にとってIT化とDXのどちらが、あるいはどのように必要かを判断する際には、現状の課題が業務効率化に留まるのか、それともビジネスモデル自体を変革する必要があるのかを問いかけることが重要です。
もし課題が「紙の書類処理に時間がかかる」といった特定の業務プロセスの改善にあるなら、まずはIT化が適切な解決策です。一方で、「競合が新しいデジタルサービスでシェアを伸ばしている」といった、ビジネスの根幹に関わる大きな課題に直面している場合は、IT化の先にあるDXの推進が求められます。
04. 事例から見るDX推進の成功とよくある課題
DX推進の具体的なイメージを持つため、ここでは具体的な成功事例からDXがもたらす価値を探るとともに、多くの企業がつまずきがちな課題とその対策について解説します。
04-1. DX推進の成功事例
【プレスリリース】データ活用における生成AI導入・活用支援サービスを提供開始 データ抽出・集計・本番移行の作業時間を8割削減

弊社にて、SQLによるデータ抽出・集計・本番移行作業に生成AIを導入したところ、一連の作業にかかる時間が月120時間から月24時間にまで短縮され、作業時間を8割削減できたという結果が出ています。
サービスの提供を通じて、企業のデータ活用における業務効率化と高度化、内製化の実現に向けた支援を加速させていきます。
プレスリリースの詳細についてはこちらから
04-2. DX推進におけるよくある課題
多くの企業がDXを推進する中で、共通の壁に直面します。その代表的な課題が「人材不足」「組織・文化の壁」「老朽化した既存システム」です。DXを成功させるには、これらの課題を認識し、計画的に対処することが不可欠です。
- ・人材不足・スキルギャップ:DXを推進するための専門的な人材が社内に不足している、あるいは既存社員のデジタルスキルがDXに必要な水準に達していない、といった課題が挙げられます。これに対する対策としては、データ活用人材の育成・確保を目的とした社内研修の実施、外部の専門家との連携、あるいは常駐サービスの活用などが考えられます。
- ・組織文化・抵抗:新しいデジタル技術の導入やビジネスモデルの変革は、従業員や組織全体から変化への抵抗を生むことがあります。また、部門間の連携不足も課題となることがあります。これらの課題を乗り越えるためには、経営層のDXに対する深い理解と強いコミットメントを促し、まずは小規模な取り組み(スモールスタート)から始めて成功体験を積み重ね、徐々に全社へと横展開していくアプローチが有効です。
- ・既存システムの老朽化:「2025年の崖」問題でも指摘される通り、老朽化した既存システムが新しい技術の導入を妨げるケースは少なくありません。システム刷新は将来の競争力を確保するための重要な投資と捉える必要があります。
05. DXとIT化に関するよくある質問(FAQ)
DXとIT化について、よく寄せられる質問とその回答をまとめました。
Q1. 「DX化」という言葉は正しいですか?
A. DXはそれ自体が「変革(Transformation)」を意味しているため、「DX化」という表現は厳密には重複表現にあたります。しかし、この言葉は広く使われており、意味は一般的に理解されています。重要なのは、これが単なるIT導入ではなく、ビジネスモデルや組織の変革を指すという本質を理解することです。
Q2. DXとデジタル化は何が違いますか?
A. デジタル化は、アナログ情報をPDFのようなデジタルデータに変換する作業(例:紙をPDFに変換)や、既存の業務プロセスをデジタル技術で効率化する取り組み(例:オンライン申請の導入)を指します。これはIT化に近い概念です。一方、DXは、これらのデジタル技術を活用し、さらに「ビジネスモデルや企業文化そのものを変革する」という、より広範で大きな概念を指します。
Q3. 中小企業でもDXは必要ですか?
A. はい、企業の規模に関わらず、今日の市場変化に対応し、競争力を維持・向上させるためにはDXは不可欠です。大企業のような大規模な投資が難しい場合でも、自社の強みを活かしたスモールスタートでのDX推進は十分に可能です。
Q4. DX推進は誰が主導すべきですか?
A. DXは全社的な取り組みであるため、経営層の強いコミットメントとリーダーシップが不可欠です。特定のIT部門や一部の部署だけでなく、事業部門との緊密な連携も極めて重要です。
Q5. DX推進にどれくらいの期間がかかりますか?
A. DXは継続的な変革プロセスであり、明確な「終わり」があるわけではありません。初期の具体的な成果が出るまでに数ヶ月から1年程度の期間を要する場合もありますが、本格的な企業全体の変革には数年以上の長期的な視点が必要とされます。
まとめ
本記事では、IT化が既存業務の効率化やコスト削減を目指す「手段」である一方、DXはデジタル技術を活用し、ビジネスモデルや組織文化、顧客体験そのものを変革して競争優位性を確立する「目的」であることを解説しました。単なるIT導入に留まらず、デジタル技術の進化や顧客ニーズの変化に対応し、「2025年の崖」を乗り越えるためには、DXが不可欠です。データ活用による新たな価値創造を目指し、自社に真に必要なのはIT化かDXかを判断し、企業競争力を高めるための具体的な一歩を踏み出すきっかけとなれば幸いです。
\ データ活用についてのご相談はメンバーズデータアドベンチャーまで /
\ 相談する前に資料を見たいという方はこちら /
▶こちらも要チェック
Webサイトやアプリの分析に欠かせないGA4ですが、その複雑さから使いこなすのが難しく感じる方も多いのではないでしょうか。本記事では、GA4を最大限に活用し、具体的なビジネス成果に繋げることを目的に、主要機能の解説から、探索レポート機能を使った実践的な深堀り分析例まで、具体的な手法を交えてご紹介します。
▶目次
01. GA4(Google Analytics 4)とは?
1-1. GA4(Google Analytics 4)とは?
GA4とは、Googleが提供しているアクセスログの解析ツールです。
アクセスログは、WEBやアプリに訪問した時の記録のことであり、ユーザーがどんな行動を取っているかを分析することができます。「4」とついているのは、バージョンナンバーに当たり、GA4が最新バージョンとなっています。
1-2. GA4とユニバーサルアナリティクス(UA)の違い
ユニバーサルアナリティクス(UA)とは、GA4の前のバージョンのことで、2024年7月でGA4に完全移行されています。
GA4になって、大きく変わった点は以下の3点です。
- セッション中心→イベント中心への計測モデルの変化
- プライバシー保護への対応
- レポート構造や機能の違い
UAは、「セッション」単位での計測モデルとなっていました。
セッションとは、ユーザーがサイトに訪問してからサイトを離脱するまでの一連の流れのことです。
例えば、どのページがよく見られているかや、どのページでユーザーが離脱してしまっているかといった、ページ遷移を基本とした分析が考慮されていました。
一方GA4は、WEBサイトの多様化やアプリの計測などを考慮し、「イベント」単位での計測モデルとなっています。
イベントとは、ユーザーが起こすアクションのことで、ページビュー、クリック、スクロールなどあらゆる操作がイベントとして計測されます。
1ページ(スクリーン)のみで成立している場合、UAで見ていたようなページ軸での分析は適していません。しかし、イベント単位にすることで、より柔軟かつ詳細にユーザー行動を分析できます。
「イベント中心」の計測モデルへの移行は、同時に分析の軸が「セッション」から「ユーザー」に変わったことも意味します。GA4では個々のイベントをユーザーに紐づけて、ユーザーを軸にした分析ができます。
昨今、プライバシー保護意識の高まりや、EUでのGDPR(一般データ保護規則)などをはじめとした規制強化により、Cookieによるトラッキングが難しくなってきています。
UAはCookieに大きく依存してユーザー行動を追跡していました。
そこでGA4では、Cookieを使用しないデータ収集方法も取り入れる等して、プライバシー保護の強化と、Cookieに依存しない計測の必要性に対応しています。
その影響としては、Cookieの同意が得られない場合、データの粒度が粗くなったり、UAと指標の定義や数値に差が生じたりすることが挙げられます。
また、分析者自身も、個人を特定できる情報の取り扱いなど、プライバシーに配慮したデータ分析をより意識する必要があります。
GA4はFirebase Analyticsというアプリ分析ツールを基盤として開発されており、UAと比べると別のツールに見えるほどレポート構造や機能が変わっています。
UAは「ユーザー」「集客」等の多数の定型レポートが用意されていましたが、GA4ではデフォルトで表示されるレポートがよりシンプルになっています。
また、GA4の最大の特徴ともいえる「探索レポート」機能により、ファネル分析や経路分析、セグメント間の比較など、より深く柔軟な分析が可能になりました。
さらに、使用するのに一定の条件はありますが、機械学習を活用した予測指標が導入されていますので、是非活用してサイトやアプリの最適化だけではなく、ビジネスへの成長にもつなげていきたいものです。
02. GA4で何が分析できる?主要機能と見るべきデータ
2-1. GA4の主要なレポート機能
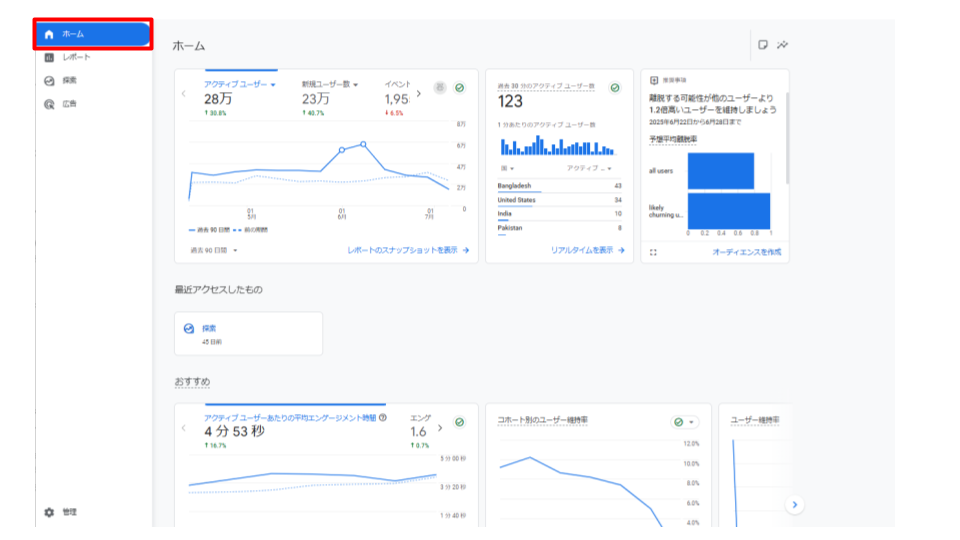
GA4のレポートは、左側のメニューから表示できます。ここでは、特に重要な4つの機能について解説します。
- ・ホーム
GA4にログインしたときに最初に表示される画面で、サイトやアプリの全体像を把握することができます。
利用状況に応じて指標がカスタマイズされ、よく見る指標を素早くチェックすることができます。指標を変更することも可能です。
また、AIによる洞察や、利用状況に応じた推奨事項(次に確認すること)なども表示され、分析を大きくサポートしてくれます。
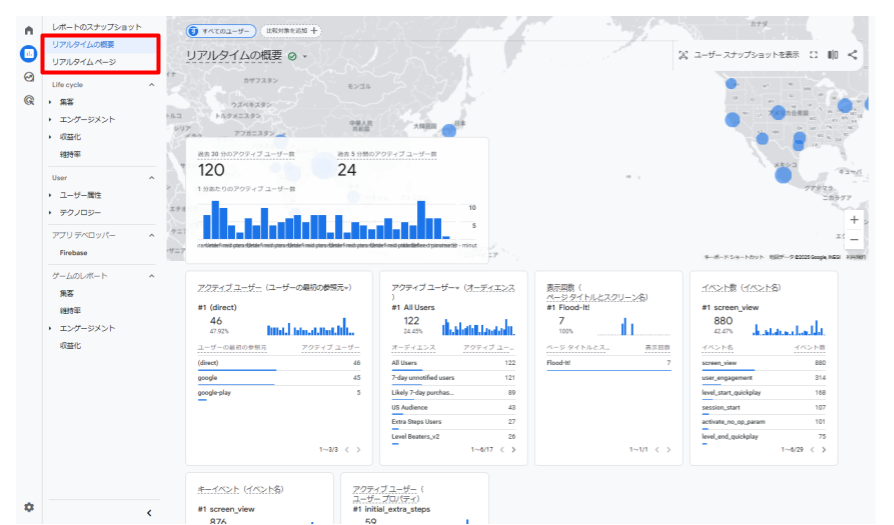
- ・リアルタイム
過去30分におけるサイトやアプリの利用状況をリアルタイムで確認することができるレポートです。
ユーザー数や、よく見られているページ(スクリーン)、ユーザーの地域などを素早く確認できます。
リリース直後の動作確認や効果測定に利用したり、デバッグビューと連携してイベント計測が正しく行われているかの確認にも利用することができます。
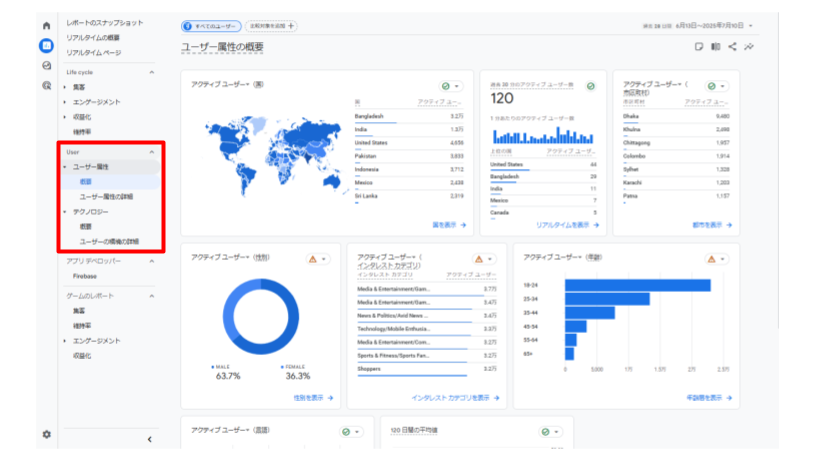
- ・ユーザー
ユーザーの「デモグラフィック情報(属性)」や「使用しているテクノロジー」に関するレポートです。
年齢、性別、インタレスト(興味・関心)などのユーザー情報から、どのようなユーザーがサイトやアプリを利用しているかの分析や、ペルソナの設定に利用することができます。
また、ユーザーがサイトやアプリにアクセスする際に利用しているデバイスやOSなどのテクノロジー情報から、技術環境に合わせた表示最適化、コンテンツ検討に利用することができます。
- ・ライフサイクル
ユーザーがアプリ・サイトにどのように関わり、どのように成長していくかを追うことができるレポートです。
「集客」では、チャネルや参照元、メディアなど、ユーザーがサイトやアプリにどこから流入してきたかを確認でき、新規ユーザーの獲得のための施策検討や、広告の効果測定などに利用できます。
「エンゲージメント」では、閲覧ページ(スクリーン)やイベント発生状況など、ユーザーがサイトやアプリ内でどのように行動しているかを確認でき、コンテンツやユーザー体験の改善に利用できます。
「収益化」では、購入数、購入経路など、サイトやアプリ内の収益に関するデータを確認でき、ECサイトなどでビジネスの収益性を評価することができます。
「維持率」では、リピーター数やユーザーコホート別のエンゲージメントなど、ユーザー定着率やLTV向上に向けた施策検討に利用することができます。
2-2. GA4で見るべき主要な指標とディメンション
GA4は、その複雑性から分析の着眼点を見失うケースが散見されます。ビジネス成果に直結する「指標」と、その深掘りのための「ディメンション」について理解することで、分析の焦点を明確にし、分析の質を高めることができます。
ここでは、GA4における主要な指標とディメンションについて、それぞれの概要とビジネスKPIへの紐づけ例を紹介します。
・指標

・ディメンション

03. 成果に直結!GA4探索機能による深掘り分析の実践
3-1. 探索レポートの基本と作成手順
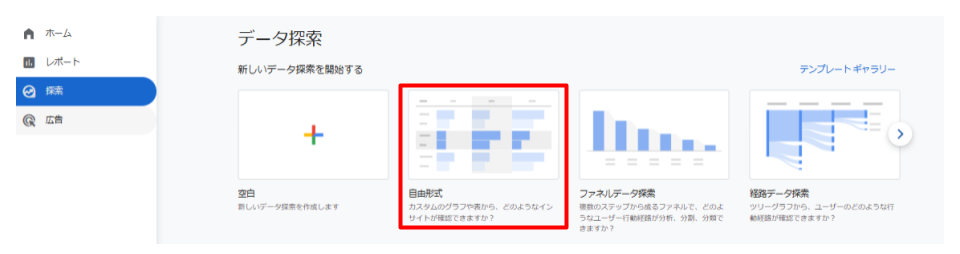
GA4の標準レポートのみでは得られない詳細なデータや、特定のビジネス課題に合わせた分析を行うためには、「探索レポート」機能を使うことが有効です。
ここでは、探索レポートの基本的な使い方から、具体的なビジネスシーンでの分析実践例を挙げています。
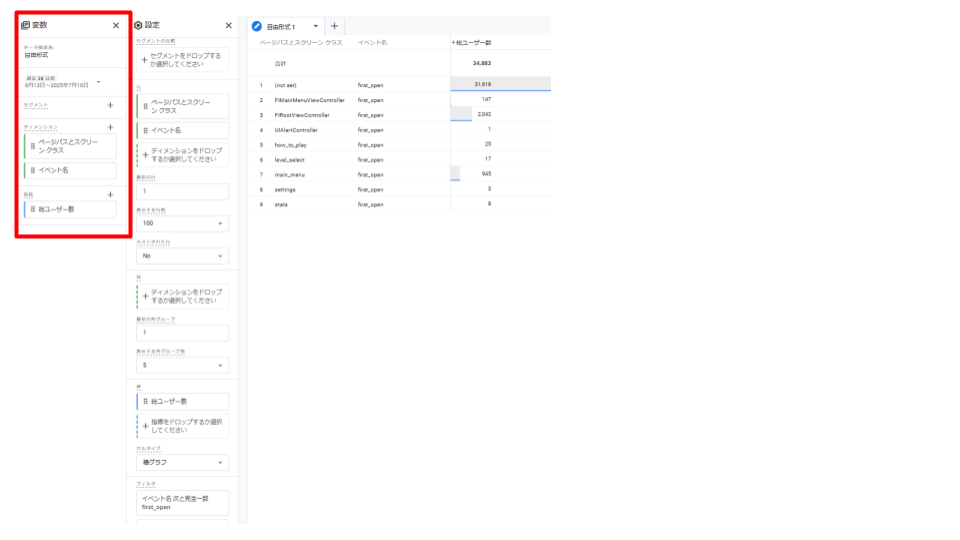
・「自由形式」レポートの作成方法
「自由形式」レポートは、クロス集計表の形式でデータを組み合わせ、可視化することができます。
- 1. GA4の「探索」から「自由形式」を選択し、新しいレポートを作成
- 2. 「データ探索名」「期間」を任意のものに変更
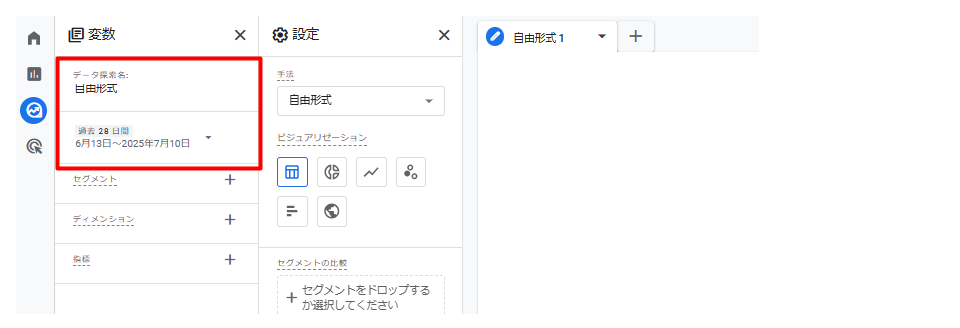
- 3. 使用したい「ディメンション」「指標」を選択
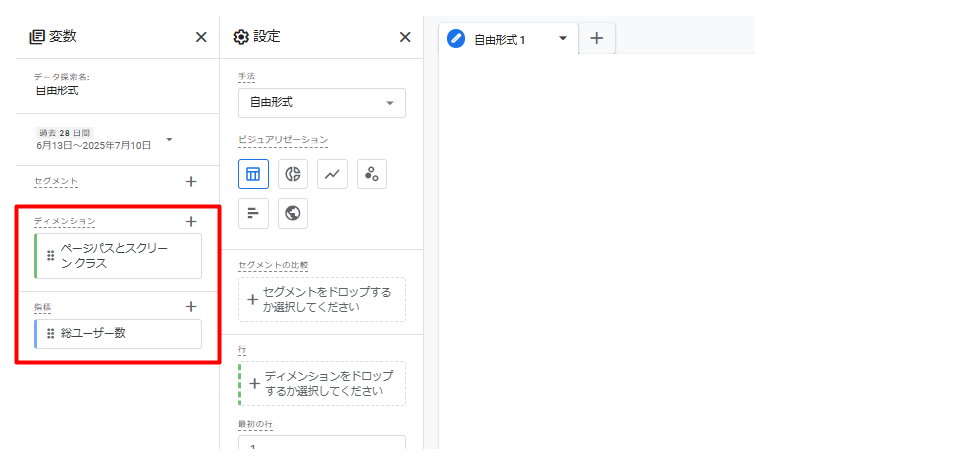
「+」を開くとカテゴリー別にディメンションと指標がまとめられているので、検索窓等から必要なものを選択します。
また、もし自動で入っているディメンションや指標があれば、随時削除したほうが見やすいです。
キャプチャの例では、ディメンションに「ページパスとスクリーンクラス」、指標に「総ユーザー数」を選択しています。
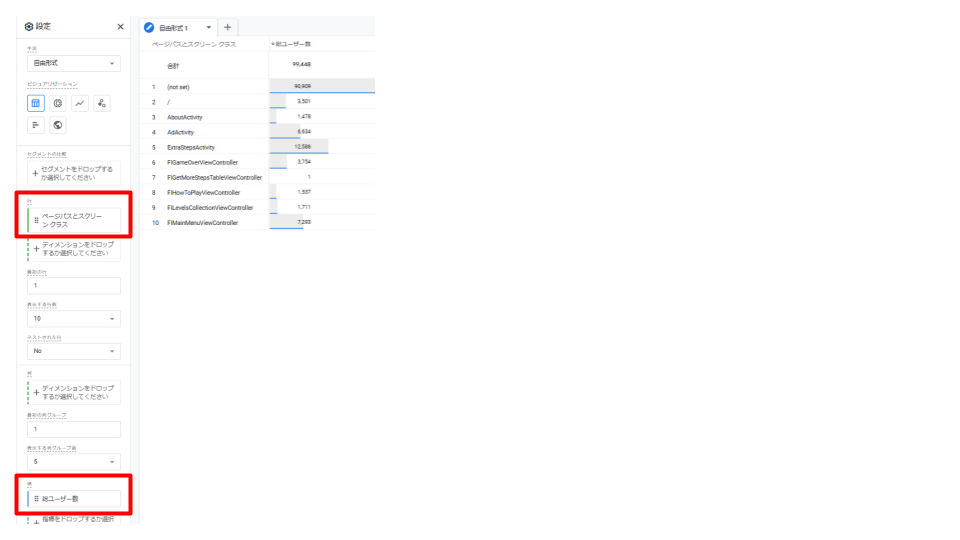
- 4. 「行」や「値」に確認したいディメンションと指標を追加します。
キャプチャの例では、行に「ページパスとスクリーン クラス」、値に「総ユーザー数」を入れて、アプリ内のスクリーン別総ユーザー数を表示させています。
別のディメンションや指標を追加したり、表示数を増やすことも可能です。
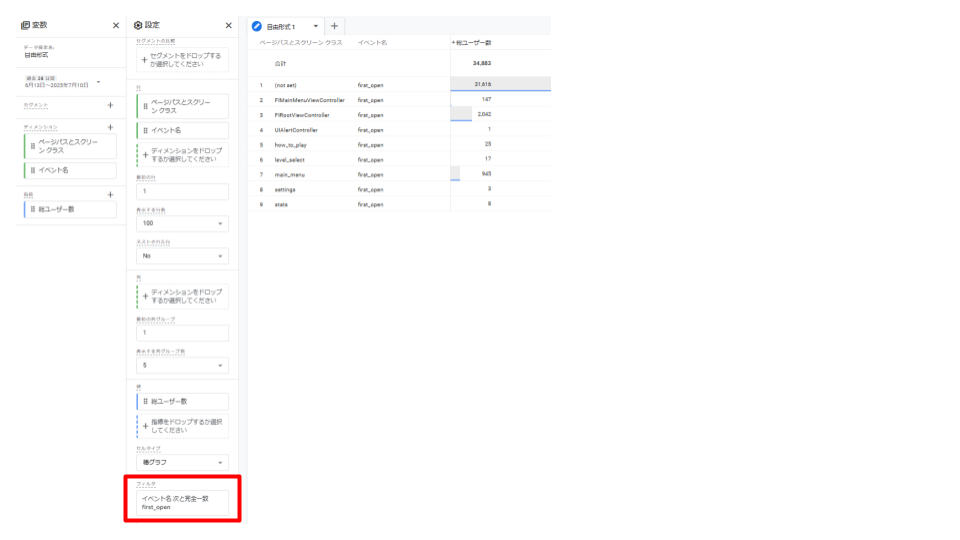
- 5. データを絞り込みたい場合「セグメント」や「フィルタ」を利用
セグメントとフィルタについては、特定の条件を絞り込むという点では同じですが、それぞれ以下のような機能となっています。
- ・セグメント:分析したい特定のユーザーやセッション、イベントのグループを切り出すための機能
- ・フィルタ:探索レポートの表示データに対して、分析したい特定の条件で絞り込みをかける機能
これで、first_openイベントが発生したスクリーン別の総ユーザー数を確認することができます。
・「タブ設定」「変数」パネルの活用方法
「タブ設定」パネルでは、レポートの手法(自由形式、コホートデータ探索など)を選択し、ディメンションや指標を配置して、データを表示させる場所です。行、列、値、フィルタ、セグメントなどの設定を調整することで、多様な視点でのレポート作成が可能です。
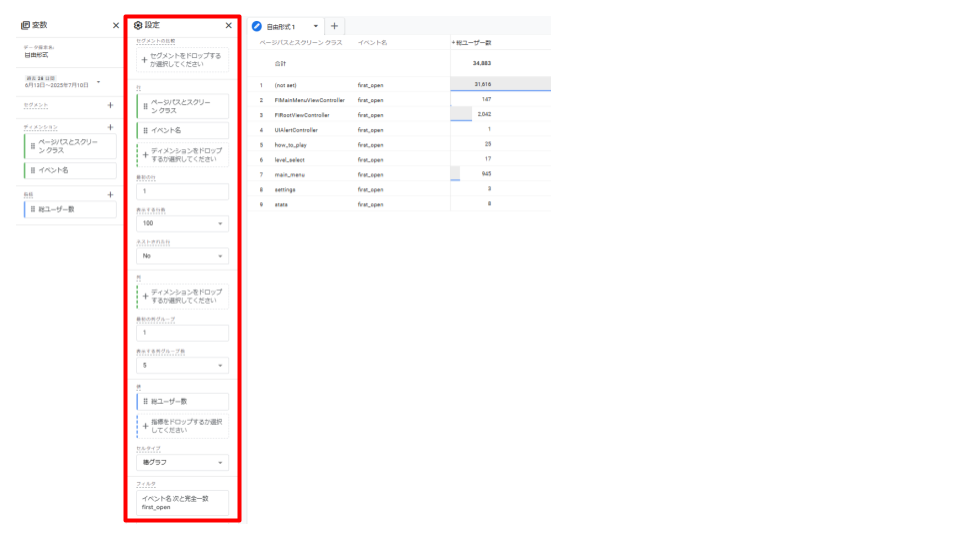
「変数」パネルで追加したセグメント、ディメンション、指標を探索レポート内で利用することができます。分析に必要な全ての要素を事前にここで準備することで、効率的にレポートを構築できます。
3-2. ECサイトの売上改善につながる分析実践例
ECサイトの売上改善には、ユーザーの購買行動を深く理解することが不可欠です。探索レポートを活用し、具体的な課題を見つけ出しましょう。
- ・特定商品の購入プロセスにおける離脱ポイント分析(経路データ探索)
ユーザーが商品ページを閲覧してから購入を完了するまでのプロセスで、どこで離脱しているかを特定します。
活用機能:経路データ探索
分析方法:- 経路データ探索レポートを作成します。
- 各ステップに「商品詳細ページ閲覧」「カート追加」「購入手続き開始」「購入完了」といった主要なイベントを設定します。
- 各ステップでのユーザー数の減少(離脱)を確認します。
- ・プロモーションチャネル別の購入貢献度分析(自由形式レポート、セッションセグメント)
どのプロモーションチャネル(広告、SNS、検索など)が最も売上に貢献しているかを評価します。
活用機能:自由形式レポート、セッションセグメント
分析方法:- 自由形式レポートを作成します。
- ディメンションに「セッションのデフォルトチャネルグループ」を設定し、「総収益」「コンバージョン(購入)」など確認したい指標を設定します。
- 特定のプロモーション施策(例:SNS広告キャンペーン)のユーザーを対象とする場合は、セグメントで該当セッションを絞り込み、チャネルグループごとの貢献度を比較します。
- ・顧客セグメント別の売上貢献度分析(自由形式レポート、ユーザーセグメント)
特定の顧客セグメント(例:リピーター、高額購入者、初回購入者など)がどのように売上に貢献しているかを把握します。
活用機能:自由形式レポート、ユーザーセグメント
分析方法:- 自由形式レポートを作成します。
- 変数パネルで、ユーザーのセグメントを作成します。(例:リピーター、高額購入者など)
- ディメンションと指標に確認したいものを設定し、該当顧客セグメントの数値を評価します。(例:総収益、コンバージョンなど)
3-3. コンテンツサイトのエンゲージメント向上分析実践例
コンテンツサイトでは、ユーザーが記事や情報にどれだけ深く関わっているかを分析し、コンテンツの質やユーザー体験の向上に繋げます。
- ・特定記事の読了率・スクロール深度分析(自由形式レポート)
特定の記事がどれだけ読まれているか、ユーザーがどこまでスクロールしているかを確認します。
活用機能:自由形式レポート
分析方法:- 自由形式レポートを作成します。
- ディメンションに「ページパスとスクリーンクラス」や「ページタイトル」など記事を特定できるものと、「イベント名」を設定します。
- フィルタで「イベント名」からスクロールを設定し、「ページパスとスクリーンクラス」で対象記事を指定します。
- 指標に「イベント数」を設定し、各スクロールイベントの発生数を確認します。
- ・人気コンテンツの閲覧経路分析(経路データ探索)
ユーザーが人気コンテンツにたどり着くまでの経路や、読了後に次に閲覧するコンテンツの傾向を把握します。
活用機能:経路データ探索
分析方法:- 経路データ探索レポートを作成し、ステップの起点または終点に人気コンテンツのページビューイベントを設定します。
- 前後のステップで、ユーザーがどのようなページを見てそのコンテンツにたどり着いたか、またはその後にどこへ移動したかを確認します。
- ・オーガニック検索からのユーザー行動分析(Googleサーチコンソール連携データ、自由形式レポート)
Googleサーチコンソールと連携したデータを用いて、オーガニック検索からの流入ユーザーが、サイト内でどのような行動をとっているかを分析します。
活用機能:自由形式レポート(GA4とSearch Consoleの連携)
分析方法:- 自由形式レポートを作成します。
- ディメンションに「Google オーガニック検索クエリ」、「ランディングページ」などを設定します。
- 指標には「コンバージョン」「イベント数」「エンゲージメント率」などを設定し、特定の検索クエリで流入したユーザーの行動を分析します。
3-4. BtoBサイトのリード獲得効率化分析実践例
BtoBサイトでは、リード獲得のため、お問い合わせフォームの最適化や、ホワイトペーパーのダウンロードユーザー分析を行います。
- ・お問い合わせフォームへの到達経路と離脱要因分析(経路データ探索)
ユーザーがお問い合わせフォームにたどり着くまでの主要な経路を把握し、離脱ポイントを特定します。
活用機能:経路データ探索
分析方法:- 経路データ探索を作成します。
- ステップに「特定ページ閲覧」→「お問い合わせページ表示」→「お問い合わせフォーム送信完了」などのイベントを設定します。
- 各ステップ間の離脱率を分析し、特に離脱率が高いステップを特定します。
- ・ホワイトペーパーダウンロードユーザーの属性と行動分析(自由形式レポート、経路データ探索、ユーザーセグメント)
ホワイトペーパーをダウンロードしたユーザーの属性を理解し、その後のサイト内行動を追跡することで、リードの質や興味関心を把握します。
活用機能:自由形式レポート、経路データ探索、ユーザーセグメント
分析方法:- ホワイトペーパーダウンロードをイベントもしくは、キーイベントに設定します。
- ユーザーの属性分析:自由形式レポートで、ディメンションに「イベント名」と「地域」「デバイスカテゴリ」など確認したい属性を設定し、フィルタでダウンロードイベントに絞り込み、ユーザー属性を分析します。
- 行動分析:ダウンロードイベントを発生させたユーザーでセグメントを作成します。このセグメントを適用した状態で、自由形式レポートや経路データ探索レポートを用いて、ダウンロード後のページ閲覧、他の資料ダウンロード、問い合わせなどの行動を追跡します。
- ・Webサイト経由のコンバージョンに貢献するチャネル分析(自由形式レポート、セッションセグメント)
お問い合わせや資料請求といったキーイベントに、どのチャネルが最も貢献しているかを分析します。
活用機能:自由形式レポート、セッションセグメント
分析方法:- 自由形式レポートを作成します。
- 「セッションのデフォルトチャネルグループ」をディメンションに、「キーイベント」を指標に設定してチャネルごとのキーイベント発生数を確認します。
- さらに複数のセグメント(例:初回訪問、リピーター)を適用して比較することで、各チャネルの特性をより深く分析します。
3-5. GA4のデータから施策立案への繋げ方
GA4で得られた分析結果を、ビジネス成果に繋げるための具体的な施策立案に活用することが重要です。
- ・分析結果から課題を特定し、仮説を立てる。
GA4で得られた「特定のページでの高い離脱率」「特定のチャネルからのコンバージョン率の低さ」「特定の顧客セグメントの購買行動の傾向」といった分析結果から、ビジネス上の「課題」を特定します。
その課題に対して、「〇〇が原因で、このような結果になっているのではないか」という仮説を立てます。 - ・仮説に基づいた施策の実行と、効果検証のための指標設定。
立てた仮説に基づき、具体的な「施策」を立案し、実行します。
施策実行後は、その効果を定量的に測るための「効果検証指標」を設定します。
GA4でこれらの指標を継続的にモニタリングし、施策の効果を検証することで、次の改善へと繋がるサイクルを回していきます。
04. GA4を使ったデータ分析に関するよくある質問(FAQ)
Q1. GA4の導入は簡単ですか?自分でできますか?
A. GA4の導入自体は比較的簡単ですが、正確なデータ計測や詳細な設定には専門知識が必要な場合があります。特にイベント設定やコンバージョン計測は、Googleタグマネージャー(GTM)の知識があるとスムーズです。
Q2. GA4のデータ分析で困った場合、どこに相談すればいいですか?
A. Google公式ヘルプ、コミュニティフォーラム、Web上の情報サイトなどで解決策が見つかることがあります。より専門的な分析や課題解決には、データ分析の専門家やコンサルティングサービスへの相談も有効です。
Q3. GA4のデータとGoogleサーチコンソールのデータは連携できますか?
A. はい、GA4とGoogleサーチコンソールを連携することで、検索クエリや検索流入ページのデータをGA4レポート内で確認できるようになり、より多角的な分析が可能です。
Q4. GA4でのデータ分析にはどのようなスキルが必要ですか?
A. アクセス解析の基本的な知識に加え、GA4のインターフェースや機能への理解、データから仮説を立てる論理的思考力、そして必要に応じてLooker Studioなどでの可視化スキルがあるとより高度な分析が可能です。
まとめ
本記事では、GA4について、その基礎からビジネス成果に繋がる実践的な分析手法までを解説しました。
GA4の主要なレポート機能や、見るべき指標・ディメンションを理解することで、より深くユーザー行動を把握し、精度の高いデータ分析が可能になります。
また、ECサイトの売上改善、コンテンツサイトのエンゲージメント向上、BtoBサイトのリード獲得効率化といった具体的なビジネス課題に対し、探索レポート機能を活用した深掘り分析の実践例を紹介しました。分析で得られた結果から課題を特定し、仮説を立て、施策を実行し、効果検証を行うPDCAサイクルを回すことが、ビジネス成長の鍵となります。GA4を最大限に活用し、データに基づいた意思決定でビジネス成果を最大化しましょう。
\ データ活用についてのご相談はメンバーズデータアドベンチャーまで /
\ 相談する前に資料を見たいという方はこちら /
▶こちらも要チェック
この記事では、顧客データ活用の基本から具体的な手法、成功のための体制づくりまでお伝えします。
▶目次
01. 顧客データ活用の重要性:データドリブン経営の要
01-1. 顧客データ活用とは?
顧客データ活用とは、企業が収集した顧客に関する多様な情報を分析し、経営戦略やマーケティング施策といった事業活動の意思決定に役立てる活動全般を指します。例えば企業は保有する顧客に関するあらゆる情報(購入履歴、Webサイト閲覧履歴、問い合わせ内容、デモグラフィック情報など)を収集・分析し、そこから顧客の行動パターン、ニーズ、嗜好を予測することができます。この予測を基に、よりパーソナライズされたマーケティング施策や商品開発、顧客体験の向上に繋げ、最終的に売上や顧客ロイヤルティの向上を目指す一連のプロセスが顧客データ活用です。
01-2. 顧客データ活用のもたらすメリット
LTVの最大化
LTVとは、一人の顧客が企業との取引を開始してから終了するまでの期間に、企業にもたらす総利益のことです。顧客データを活用することで、このLTVを最大化することができます。
- ・顧客の離反防止:顧客が離れていく兆候を早期に察知し、適切なタイミングでクーポンやパーソナライズされた提案を行い、顧客の継続利用を促します。
- ・アップセル・クロスセル:顧客が購入した商品やサービスに関連する上位モデルや別の商品を提案し、顧客単価と購入頻度を向上させます。
- ・ロイヤルティ向上施策:優良顧客を特定し、限定イベントへの招待や特別割引など、個別のインセンティブを提供し、顧客の企業への愛着を深め、長期的な関係を構築します。
顧客満足度向上
顧客データを活用することで、顧客一人ひとりのニーズや期待を深く理解し、それに応じたパーソナライズされた体験を提供します。
- ・パーソナライズされたコミュニケーション:顧客の興味や購買履歴に基づいたメールマガジンやプッシュ通知を送り、顧客にとって本当に価値のある情報を提供できます。
- ・最適な顧客サポート:顧客の過去の問い合わせ履歴や購入商品を把握し、問い合わせ時により迅速かつ的確なサポートを提供し、顧客のストレスを軽減します。
- ・シームレスな顧客体験:顧客がどのチャネル(Webサイト、アプリ、店舗など)を利用しても、過去の行動履歴や好みが反映された一貫したサービスを提供し、スムーズで快適な顧客体験を実現します。
マーケティング施策最適化
顧客データを分析することで、限られたマーケティング予算を最も効果的に活用し、施策のROI(投資対効果)を最大化します。
- ・ターゲット設定の精度向上:顧客のデモグラフィック情報、行動データ、購買データなどに基づいて、最も反応しやすい顧客層を特定し、ターゲットを絞り込んだ広告配信やキャンペーンを実施します。無駄な広告費を削減し、コンバージョン率を高めます。
- ・メッセージとクリエイティブの最適化:どのメッセージやデザインが特定の顧客セグメントに響くのかをデータに基づいて検証し、最も効果的なクリエイティブを開発します。
- ・チャネルの選択:顧客がどのメディアやプラットフォームを好んで利用しているかを把握し、効果的なチャネルにリソースを集中させ、リーチとエンゲージメントを最大化します。
- ・リアルタイムな改善:施策の効果をリアルタイムで測定し、データに基づいてPDCAサイクルを迅速に回し、常に最適なマーケティング戦略へと改善します。
新サービス・商品開発など
顧客データは、単に既存のサービスを改善するだけでなく、市場に求められる新たなサービスや商品を開発するための貴重な源泉となります。
- ・潜在ニーズの発見:顧客の行動データや問い合わせ内容、SNS上の言及などを分析し、顧客自身も気づいていないような潜在的なニーズや不満点を発見します。
- ・市場トレンドの把握:特定の商品の売上動向や顧客の嗜好の変化をデータから読み取り、今後の市場トレンドを予測し、先手を打った商品開発を進めます。
- ・新機能の優先順位付け:既存サービスの利用状況や顧客からのフィードバックを分析して、どの機能を追加・改善すれば顧客満足度や利用率が最も高まるかを判断します。
- ・パーソナライズされた商品の提供:顧客の個別のデータに基づき、カスタマイズされた商品やサービスの開発に繋げます。
02. 顧客データを分析・活用する具体的な方法
02-1. 顧客データの種類と収集方法
顧客データは大きく「定量データ」と「定性データ」に分けられますが、近年注目されている「ゼロパーティデータ」も含め、多角的に収集することが望ましいです。
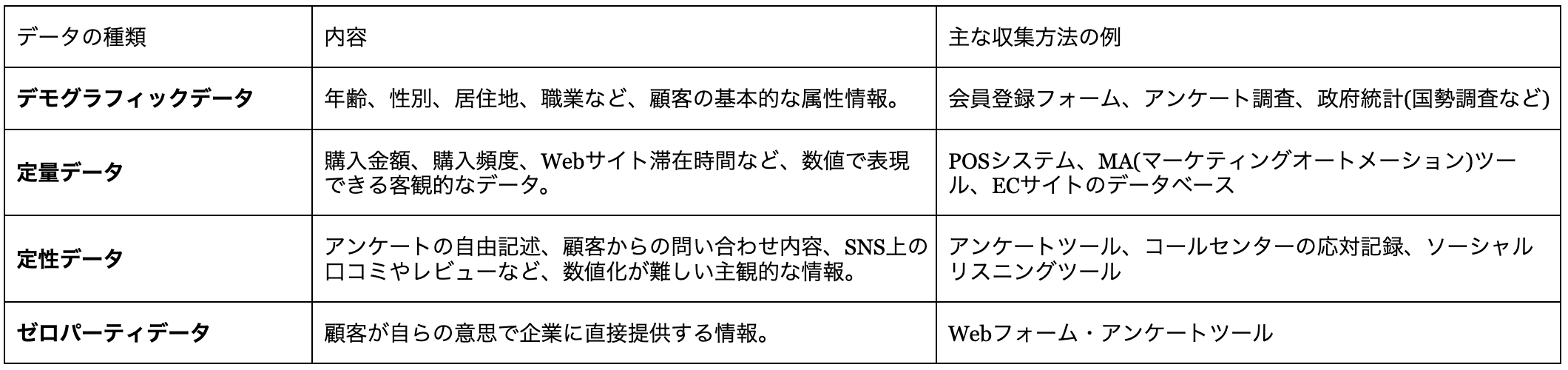
定量データ(購買履歴、Webアクセスログなど)
数値で表せる客観的な情報です。顧客の行動を数字で捉え、傾向を分析します。
- ・購買履歴:誰が、いつ、何を、いくらで買ったか、購入頻度、購入経路など。
- ・Webアクセスログ:サイト訪問回数、滞在時間、閲覧ページ、クリック率など。
- ・アプリ利用データ:起動回数、利用時間、利用機能、課金履歴など。
定性データ(顧客の声、アンケートなど)
数値化できない顧客の感情や意見、動機など、深層的な情報です。顧客の「なぜ」を理解するのに役立ちます。
- ・顧客の声(VOC:Voice Of Customer):問い合わせ、SNS上の投稿、レビューサイトのコメントなど。
- ・アンケート・インタビュー:サービスに対する満足度、改善点、利用動機など、顧客の直接的な意見や感想。
- ・NPS(ネットプロモータースコア):顧客ロイヤルティを測る指標。
ゼロパーティデータ
顧客が自らの意思で企業に直接提供する情報です。顧客自身の明確な意思が反映されており、最も正確なニーズを把握できます。
- ・Webサイトでの興味や関心事の選択。
- ・マイページでのプロフィール設定(趣味、家族構成など)。
- ・診断コンテンツの結果。
収集方法(自社システム、CRM、Webフォーム、IoTデバイスなど)
- ・自社システム:ECサイトの購買システム、会員管理システムなど、企業が独自に運用しているシステム。
- ・CRM(顧客関係管理)システム:顧客情報、購入・問い合わせ履歴などを一元管理(Salesforceなど)。
- ・Webフォーム・アンケートツール:会員登録フォームなど、顧客が直接入力する形でデータを収集。
- ・Webアクセス解析ツール:Webサイト訪問者の行動を自動収集(Google Analyticsなど)。
- ・IoTデバイス:スマート家電などから利用状況を収集。
02-2. 顧客データの整理・統合
収集した顧客データは、そのままでは分析や活用が難しい場合がほとんどです。そのため、効果的に利用するためには「整理・統合」のプロセスが不可欠です。異なるシステムや形式で蓄積されたデータは、そのままでは正確な分析が困難であり、データの価値を著しく損なうからです。
散在データの一元化と顧客軸での統合
企業内に散らばる顧客データ(例:EC購買履歴、店舗POS、問い合わせ記録など)を一つの場所に集めるのがデータの一元化です。さらに、これらを「同じ顧客」の情報として紐づけるのが顧客軸での統合です。これにより、分断されていた顧客情報を一つにまとめ、多角的な顧客像を正確に把握し、データ分析の精度と効率を飛躍的に高めることができます。
データの重複排除、表記揺れ統一、欠損値補完などのデータクレンジング
データクレンジングは、収集・統合したデータの品質を高める重要な作業です。具体的には、同じ顧客情報が複数ある場合の重複排除 、会社名や住所などの表記揺れを統一して正確性を確保します。また、必要なデータが抜けている部分(欠損値)を補ったり、適切に処理したりします。これにより、データ分析の精度が向上し、誤った判断を防ぎ、より信頼性の高い施策立案が可能になります。
02-3. 顧客データ分析の代表的な手法
セグメンテーション分析
顧客全体を、特定の共通の特性(年齢、購買行動、興味など)に基づいて、意味のあるグループ(セグメント)に分類する手法です。これにより、漠然とした「顧客」ではなく、「どのような特徴を持つ顧客が、どう行動するか」を具体的に把握できるようになります。活用事例をご紹介します。
- ・アパレル企業:顧客を「20代女性、トレンド志向」「40代男性、ビジネス重視」といったセグメントに分け、それぞれのセグメントに合った新作情報やセール情報を、最適なチャネル(SNS、メールマガジンなど)で配信することで、購買率を向上させます。
- ・旅行会社:顧客を「家族旅行好き」「一人旅愛好家」「温泉リピーター」などに分類し、各セグメントに特化した旅行プランを提案したり、パーソナライズされたキャンペーンを展開したりすることで、予約率を高めます。
RFM分析
顧客の購買データから優良度を測る手法です。R(Recency:最新購入日)、F(Frequency:購入頻度)、M(Monetary:購入金額)の3指標で顧客をランク付けします。これにより、「優良顧客」「休眠顧客」などに分類し、各セグメントへ最適なアプローチを検討し、効果的な売上向上を目指します。
- ・ECサイト:RFM分析で「Rが高く、FとMも高い」顧客を「優良顧客」と定義。これらの顧客には、新商品の先行予約案内や限定クーポンを配布し、ロイヤルティをさらに高める施策を実施します。
- ・小売店:「Rは高いが、FとMが低い」顧客(新規顧客や一度だけ購入した顧客)には、再来店を促すための初回限定割引や、関心を持ちそうな商品のレコメンデーションを行うことで、リピート購入へ繋げます。
バスケット分析
顧客が「一緒に購入する商品の組み合わせ」を発見する分析手法です。スーパーマーケットのレジ通過データ(バスケット)から、どの商品とどの商品が同時に買われる傾向があるのかを明らかにします。主に「もしXが購入されたら、Yも購入される可能性が高い」といった関連ルールを見つけ出します。
- ・レコメンデーション機能:「この商品を買った人はこんな商品も買っています」といったレコメンデーション機能を強化します。
- ・セット販売:「化粧水」と「乳液」が一緒に買われる傾向が強いと分かった場合、両方の商品を近くに配置することで、ついで買いを促進します。
行動分析
顧客がWebサイトやアプリ内、実店舗などで「どのような行動をとったか」を詳細に追跡し、その背景にある意図や心理を理解する分析手法です。特にデジタル行動データ(クリック、スクロール、ページ遷移、フォーム入力など)が主な対象となります。
- ・Webサイト改善:顧客が商品ページからカートに入れないボトルネックを行動分析(ファネル分析、ヒートマップ)で特定。商品ボタンの配置や文言を改善し、カート追加率を向上させます。
- ・パーソナライズ:無料体験レッスンを予約したが未受講の顧客に対し、行動データに基づきリマインドメールを自動送信。受講を促し、次の行動へ繋げます。
03. 顧客体験(CX)改善に繋がるデータ活用事例
03-1. 顧客ロイヤルティの可視化
・課題:ロイヤルティの高い顧客低い顧客を分類して可視化したい
ロイヤルティの高い顧客、低い顧客を分類し可視化することで、今後集客するターゲットへ共通認識を持ちたいという要望がありました。
・施策:RFM分析で顧客をスコアリング
RFM分析により顧客をスコアリングし既存顧客を5つに分類し、部門責任者と合意形成しロイヤルティの定義を明確化。ダッシュボードにて月次の顧客層ごとの人数やLTV、来店回数を可視化しました。
・結果:共通認識が生まれ施策検討に活用できるように
クライアント社内でロイヤリティが高い顧客の定義について共通認識が生まれ、その数が定点観測できるように。施策検討や効果検証の際にダッシュボードの数値を活用することが可能となりました。
03-2. 社内向け顧客データ分析アプリの開発
・課題:データ分析に時間がかかっていた
社内データを手軽に抽出・分析できる環境がなく、大量にあるデータの分析に時間がかかっていました。
・施策:アプリ開発・実装からマニュアル作成まで
分析の要件を整理、施策に反映できるデータの選定から実施し、システム部と連携しながら1ヵ月でアプリを開発。運用マニュアルまで整備し、社内アプリケーションとして内製化しました。
・結果:誰でも分析が可能に
誰でも社内データを分析できるようになり、効果的な施策への反映がすぐにできるようになりました。分析のコストや工数の削減と、データから施策への反映ができる環境構築に寄与しました。
04. 顧客データ活用のための体制構築と注意点
顧客データの活用を成功させるためには、優れたツールを導入するだけでは不十分です。 明確な目的設定から、それを推進する組織体制、そしてデータを安全に扱うためのルール作りまで、盤石な基盤を構築することが不可欠といえます。
この章では、データ活用を軌道に乗せるための体制構築の要点と、遵守すべき重要な注意点を解説します。
04-1. 顧客データ活用の目的と目標の明確化
・具体的なビジネス目標(例:LTVを〇%向上させる)を設定。
顧客データ活用は、「何のために」行うのかを明確にするのが最重要です。漠然と始めるのではなく、「LTV(顧客生涯価値)を15%向上させる」「新規顧客獲得数を20%増やす」のように、具体的で測定可能な数値目標を設定します。これにより、データ活用の方向性が定まり、後続の施策や分析が効果的に進められます。
・目標達成のためのKPI(重要業績評価指標)を設定。
設定したビジネス目標が達成されているかを測るには、KPI(重要業績評価指標)が不可欠です。例えば、LTV向上目標なら「顧客単価」「購入頻度」「継続利用期間」などがKPIとなります。KPIを定めることで、データ活用施策の成果を定量的に評価し、PDCAサイクルを回して継続的な改善を図る基盤を築くことができます。
04-2. 顧客データ活用を推進する組織体制と人材
・データ専門部署(データ統括部など)の設置、部門横断的なプロジェクトチームの組成。
顧客データ活用を成功させるには、データ専門部署の設置や、各部門が連携する部門横断的なプロジェクトチームの組成が不可欠です。データ統括部などが中心となり、データ収集から分析、施策実行までを一貫して管理・推進する体制を整えることで、組織全体でデータドリブンな意思決定が可能になります。
・データサイエンティスト、データアナリスト、データエンジニアといったデータ活用人材の役割。
データ活用には専門人材が欠かせません。データサイエンティストは高度な分析やモデル構築、データアナリストはデータからのインサイト抽出と可視化、データエンジニアはデータ基盤の構築・運用を担います。これらの専門家が連携することで、データをビジネス価値に変えるサイクルを回します。
・人材不足への対応(育成、外部専門家との連携、常駐サービスの検討)。
データ活用人材は需要が高く、不足しがちです。これに対応するためには、社内での人材育成(研修、OJT)、外部のデータ専門家との連携(コンサルティング契約)、あるいは常駐サービスの活用が有効です。これにより、必要な専門知識とスキルを確保し、データ活用を継続的に推進できる体制を構築します。
04-3. データガバナンスとセキュリティ・プライバシー
・データの利用ルール、管理責任者の明確化、データ品質維持の仕組み。
顧客データ活用では、データの利用ルールを明確にし、管理責任者を定めるデータガバナンスが不可欠です。これにより、データが適切に扱われることを保証します。また、分析や施策の精度を高めるためには、データ品質を維持する仕組み(定期的なクレンジング、更新など)も重要です。これにより、データに基づいた意思決定の信頼性が向上します。
・個人情報保護法、GDPRなどの法規制遵守、セキュリティ対策の重要性。
顧客データの活用においては、セキュリティ対策とプライバシー保護が最重要です。個人情報保護法やGDPRなどの法規制遵守 は絶対条件であり、情報漏洩や不正利用を防ぐための厳重なセキュリティ対策が求められます。顧客からの信頼を維持し、企業のブランドイメージを守るためにも、これらの対策は経営の根幹をなすものと認識すべきです。
04-4. スモールスタートと継続的な改善(PDCA)
・一度に全てを変えようとせず、小さく始めて成功体験を積み重ねるアプローチ。
顧客データ活用は、一度に大規模なシステム導入や分析をせず、小さく始めるのが賢明です。特定の部門や簡単な分析から着手し、成功体験を積み重ねることで、組織全体にデータ活用の重要性や効果を理解されやすいです。これにより、無理なく、そして着実に、データドリブンな文化を浸透させることができます。
・PDCAサイクルを回す。
データ活用は、一度やったら終わりではありません。PDCA(Plan-Do-Check-Action)サイクルを回し、継続的に改善することが重要です。データを分析して施策を「計画」し、「実行」します。その「結果を評価(Check)」し、さらに良くするための「改善策を検討・実行(Action)」します。この繰り返しで、データ活用の精度と効果を高めていきます。
・小さな成功体験を全社に共有する。
スモールスタートで得られた小さな成功体験は、積極的に全社で共有しましょう。成功事例や具体的な成果を共有することで、他の部門や従業員のデータ活用への関心を高め、協力を促せます。成功体験は、データ活用への投資の正当性を示し、組織全体のモチベーション向上とデータドリブンな文化醸成に貢献します。
05. 顧客データ分析をサポートするツールとサービス
顧客データ分析には、BI(Business Intelligence)ツールやMA(マーケティングオートメーション)ツール、CDP(カスタマーデータプラットフォーム)など多様なサービス・プラットフォームが活用されています。
05-1. 主要な顧客データ分析ツール
- ・CRM(顧客関係管理システム):顧客とのあらゆる接点情報を一元管理するシステムです。顧客情報や購入履歴、問い合わせなどを統合し、営業・マーケティング・サポート部門が共有。これにより、顧客関係を強化し、LTV向上などに役立つ分析も可能です。
- ・MA(マーケティングオートメーション):マーケティング活動を自動化・効率化するツールです。顧客のWeb行動やメール反応データを収集・分析し、その情報に基づき、パーソナライズされたメール配信やWebサイトの最適化などを自動実行します。大規模な顧客アプローチを効率的に行えます。
- ・BIツール(ビジネスインテリジェンスツール):社内の大量データを統合し、グラフなどで視覚的に分かりやすく表現するツールです。顧客データだけでなく、売上や在庫など多様なデータを分析し、ビジネスの傾向や問題点を明確にします。経営層や各部門が迅速な意思決定を行うための洞察を提供します。
- ・CDP(カスタマーデータプラットフォーム):オンライン・オフライン問わず、あらゆる顧客データを統合・管理・分析することに特化したプラットフォームです。顧客一人ひとりの詳細なプロファイルを構築し、他のシステム(CRM,、MA、BIなど)と連携。リアルタイム性と柔軟なデータ連携が強みで、パーソナライズされた顧客体験を提供します。
05-2. ツール導入時の選び方と注意点
導入成功のためには、自社の目的や運用体制に合ったツールを選定し、サポートやコスト面、データ連携のしやすさも事前に確認することが重要です。単なる機能比較でなく、社内リソースやデータ量との適合性を見極めないと、効果が限定的になったり運用が定着しなかったりするので注意が必要です。

05-3. 外部専門家・常駐サービスの活用メリット
外部専門家や常駐サービスを活用すれば、社内に不足しがちなデータサイエンスの専門スキルや最新ノウハウをスピーディに獲得し、事業成長を力強く後押しできます。
- ・専門知識・スキルの補完、社内リソース不足の解消。
外部専門家や常駐サービスを活用する最大のメリットは、社内のデータ分析スキル不足を迅速に補完し、高度な分析や最新ツールへの対応を可能にします。これにより、自社育成の時間とコストを削減し、限られた社内リソースの課題を解消しながら、データ活用をすぐに始められます。 - ・客観的な視点での課題発見と解決策の提案。
外部専門家は、社内の慣習にとらわれず、客観的な視点から課題を発見し、本質的な解決策を提案します。これにより、自社だけでは気づけない非効率な点や新たな可能性を見つけ出し、より効果的な戦略立案や施策実行に繋げられます。 - ・データ分析ノウハウの社内定着支援。
弊社データアドベンチャーカンパニーは、分析実行だけでなく、そのノウハウを社内に定着させる支援も行います。共同作業や研修を通じて、社内人材のデータリテラシーやスキル向上を促し、自社で継続的にデータ活用できる体制構築に貢献します。
また、株式会社ベネッセコーポレーションの「Udemy」事業では、メンバーズデータアドベンチャーカンパニーの常駐データサイエンティスト・データアナリストが、事業や顧客に深く寄り添いながら高度な分析を実施。組織力強化とビジネス成長に直結するアウトプットを提供しています。
詳しくはこちらの導入事例ページをご覧ください→常駐メンバーの高度な技術が「Udemy」事業のさらなる成長に貢献
![]()
✔️採用にコストをかけず実現するプロの伴走支援
✔️データ整備から内製化までの一貫サポート
サービスの詳細、支援内容、導入事例は下記ページで公開しています。
▶︎サービス内容:データ領域 プロフェッショナル常駐サービス
▶︎導入事例:導入事例 | メンバーズデータアドベンチャー
\ データ活用についてのご相談はメンバーズデータアドベンチャーまで /
06. 顧客データ活用に関するよくある質問(FAQ)
Q1. 顧客データ活用の最初のステップは何ですか?
・A. まずは「何のために活用するのか」という目的を明確にすることです。具体的なビジネス課題や目標を設定し、それに必要なデータは何かを洗い出すことから始めましょう。例えば、「優良顧客の離反率を半年で5%改善する」といった具体的な目標を設定することで、分析すべきデータ(例:購買頻度、最終購買日、Webサイトの閲覧履歴など)が自ずと明確になるでしょう。まずはビジネス上の課題を洗い出し、データ活用によって解決したいことを一つに絞り込むことから始めてください。
Q2. 顧客データを収集する際の注意点は?
・A. 個人情報保護法などの法的規制の遵守が最も重要です。顧客からの適切な同意を得ること、セキュリティ対策を徹底すること、そして収集する目的を明確にすることが挙げられます。具体的には、プライバシーポリシーで利用目的を明示して同意を得る、強固なパスワード設定やデータの暗号化といったセキュリティ対策を徹底する、といった対応が不可欠でしょう。
Q3. 顧客データ活用で成果を出すには時間がかかりますか?
・A. 取り組みの規模や初期データの状態によりますが、短期間で部分的な成果を出すことは可能です。しかし、LTV向上やビジネスモデル変革といった大きな成果には、継続的な取り組みとPDCAサイクルの実践が必要です。
Q4. どのような人材が顧客データ活用には必要ですか?
・A. データ収集・加工ができるエンジニア、データを分析し課題を発見するアナリストなど、様々なスキルを持つ人材が必要です。社内での育成が難しい場合は、外部専門家の支援を検討することも有効です。
まとめ
顧客データ活用は、売上向上とLTV最大化、顧客満足度向上に不可欠です。まず、購買履歴(定量データ)や顧客の声(定性データ)、顧客が直接提供するゼロパーティデータなど、多様なデータを収集します。これらを一元化し、重複排除や表記統一といったデータクレンジングで品質を高めます。
分析には、顧客をグループ分けするセグメンテーション、購買頻度などで優良度を測るRFM分析、併売傾向を見るバスケット分析、サイト内行動を追う行動分析が有効です。
体制構築では、目的・目標の明確化とKPI設定が重要。データ専門部署の設置や専門人材の確保(外部活用も視野に)、データガバナンスとセキュリティ対策も徹底しましょう。CRM、MA、BIツール、CDPなどのツールを適切に選び、スモールスタートでPDCAを回し、成功体験を共有しながら継続的に改善していくことが成功の鍵です。
\ データ活用についてのご相談はメンバーズデータアドベンチャーまで /
\ 相談する前に資料を見たいという方はこちら /
▶こちらも要チェック
DXが進む今、企業の競争力を左右するのは「データの使い方」です。
本記事では、ビジネスの成果を引き出すために欠かせない「データマネジメント」の基本から、成功のポイント、よくある課題とその解決策までを体系的にご紹介。
なぜ今データマネジメントが重要なのか、どう取り組めば成果につながるのかを、実践的な視点でお伝えします。
▶目次
![]()
✔️採用にコストをかけず実現するプロの伴走支援
✔️データ整備から内製化までの一貫サポート
サービスの詳細、支援内容、導入事例は下記ページで公開しています。
▶︎サービス内容:データ領域 プロフェッショナル常駐サービス
▶︎導入事例:導入事例 | メンバーズデータアドベンチャー
\ データ活用についてのご相談はメンバーズデータアドベンチャーまで /
01. データマネジメントとは?その定義と役割
01-1. データマネジメントの基本的な定義
「データマネジメント」とは、組織が保有するあらゆるデータを、正しく・安全に・有効に管理・活用するための一連のプロセスや仕組みを指します。
単にデータを「保管」するだけでなく、「収集・保存・加工・分析・廃棄」までのライフサイクル全体を適切に管理し、「整える・守る・活かす」ことでデータの価値を最大化する取り組みです。
例えば、お金を管理するために経理部門が専門的な知識とルールに基づいて活動するのと同様に、データという資産を専門的に管理する機能と捉えると理解しやすいでしょう。
データマネジメントは、アドホックなIT作業ではなく、財務管理や人事管理と同様に確立された専門的なビジネス機能です。
企業がデータに基づいた意思決定を行うためには、信頼できるデータ基盤が不可欠です。そのための土台を築くのが、データマネジメントなのです。
01-2. データマネジメントが担う主要な役割
データマネジメントは、企業のデータ活用において多岐にわたる重要な役割を担っています。ここでは主要な3つの役割、「データの品質向上」「セキュリティの確保」「データガバナンスの構築」について説明します。
- ・データの品質向上:
データの正確性・一貫性・完全性を確保し、信頼できる情報基盤を構築することで、判断ミスや業務トラブルを防ぎ、意思決定の精度を高めます。 - ・セキュリティの確保:
アクセス制御や暗号化、監査体制を通じて、データの機密性・整合性・可用性を維持。不正アクセスや漏洩のリスクを低減し、企業の信頼性を守ります。 - ・データガバナンスの構築:
データの所有者・責任者・利用ルールを明確化し、全社統一のデータ活用体制を整備。誰がどのデータをどのように扱うかを明確にすることで、適切な利用と統制を実現します。
国際的な非営利団体であるDAMA(国際データマネジメント協会)が提唱するフレームワーク「DAMAホイール」では、これらを含む複数の知識領域の中心に「データガバナンス」が位置づけられています。
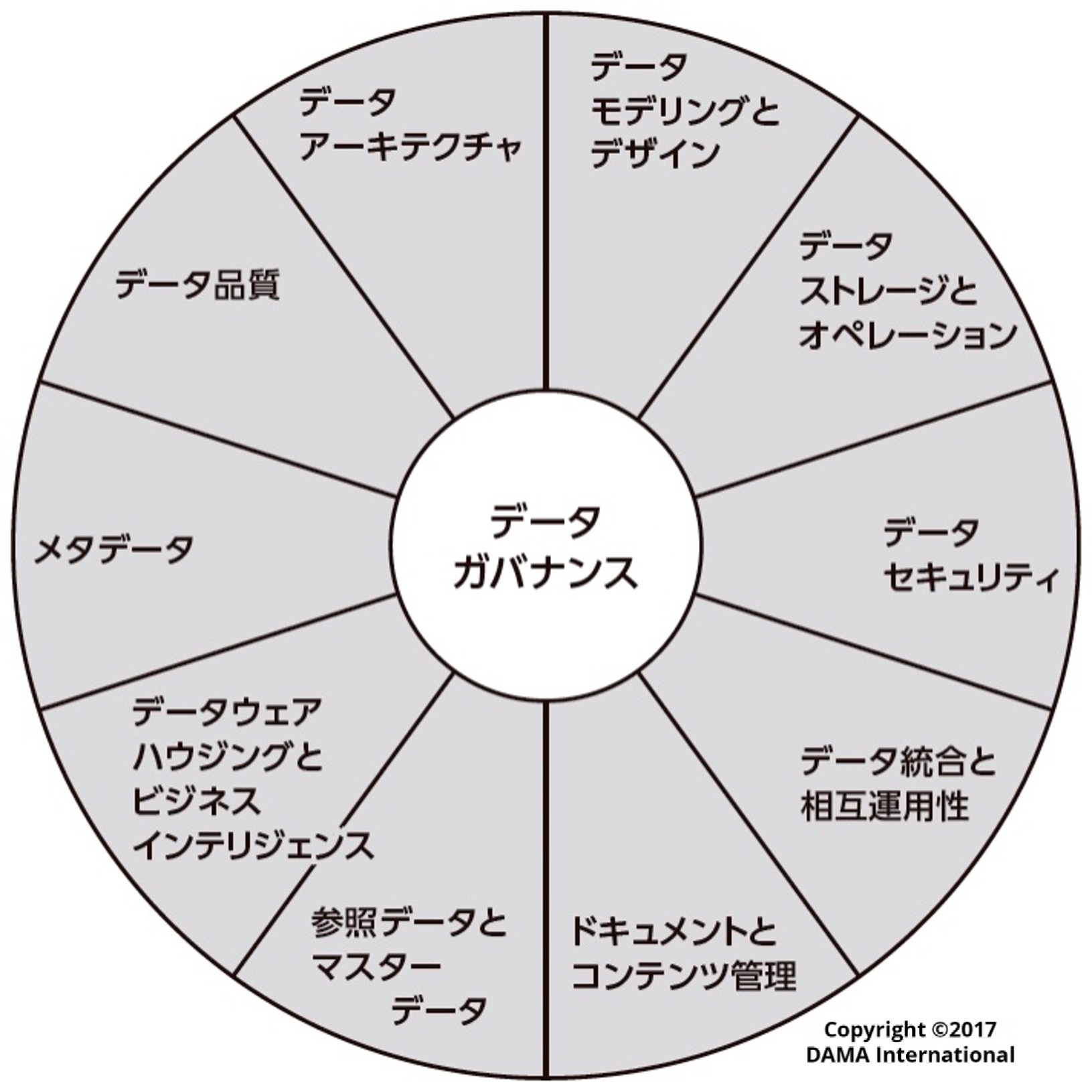
出所:『データマネジメント知識体系ガイド 第二版』 DAMA International編著、DAMA日本支部、Metafindコンサルティング株式会社 監訳、日経BP
データガバナンスという土台の上に、初めて信頼できるデータ活用が成り立ちます。このように、データマネジメントは、組織が安心してデータを活用するための秩序を作り、その資産価値を守り、高めるための根幹的な役割を果たしているのです。
02. なぜ今、データマネジメントがDX推進に不可欠なのか?
適切なデータマネジメントは、DX推進を加速させ、企業に非常に大きなメリットをもたらします。
ここでは、効果的なデータマネジメントがもたらす3つの決定的なメリット、すなわち「事業成長と顧客体験の向上」「業務効率化とコスト削減」、そして「法的リスクの軽減」に焦点を当て解説します。
02-1. 事業成長と顧客体験の向上を実現する
データマネジメントによって適切に整備された信頼性の高いデータは、経営判断、商品開発、マーケティングの精度を高め、新たな事業機会の創出につながります。総務省の調査によれば、DXによるデータ利活用は経済に大きなインパクトを与え、製造業で約23兆円、非製造業で約45兆円もの売上高押し上げ効果があったと試算されています。
参照:「令和3年版情報通信白書」(総務省)
https://www.soumu.go.jp/johotsusintokei/whitepaper/ja/r03/html/nd1124a0.html(2025年8月18日に利用)
これは信頼できるデータに基づき、顧客の行動や購買履歴を的確に把握することで、顧客一人ひとりのニーズに応じたサービス提供が可能になるためです。
その結果、顧客満足度が向上し、売上や企業価値の向上を通じて、事業成長が促進されます。データマネジメントによって整備された信頼性の高いデータ基盤こそが、こうしたデータドリブンな成長戦略を実現するための不可欠な前提条件だと言えます。
02-2. 業務効率化とコスト削減に貢献する
信頼性の高いデータ基盤の構築により、部門間の連携が進み、手作業によるデータ収集や統合作業が大幅に削減されます。多くの企業で、DXに期待する成果のトップとして「業務プロセスを変革し、生産性を向上する」ことが挙げられています。
データマネジメントがこれを実現する理由は、重複データや部門ごとに分断された情報を整理・統合し、「信頼できる唯一の情報源(Single Source of Truth)」を構築するからです。これにより、データを探したり手作業で集計したりする非効率な時間の削減、システム運用や人件費などのコスト削減が実現できます。
その結果、社員は付加価値の高い業務に集中でき、生産性の向上にもつながります。
02-3. 法的・規制要件への対応とリスク軽減
個人情報保護法やGDPR(※)など、国内外でデータ保護に関する規制が強化される中、適切なデータマネジメントはコンプライアンス遵守に不可欠です。
個人情報保護委員会への漏えい等事案の報告件数は年々増加し、2024年度には189件に達するなど、データ漏洩リスクはかつてないほど高まっています。
また、東京商工リサーチの調査では、2023年に発生した情報漏洩・紛失事故による対象人数は過去最多の4,090万人分にのぼりました。これらのインシデントは、不正アクセスだけでなく、従業員の誤操作といった内部要因も多く含みます。
参照:「2024年「上場企業の個人情報漏えい・紛失事故」調査」(東京商工リサーチ)
https://www.tsr-net.co.jp/data/detail/1200872_1527.html(2025年8月18日に利用)
データの取り扱いや管理体制を明確にし、記録・監査・ログ管理を徹底することで、こうした情報漏洩や改ざんといったセキュリティリスク、さらには法令違反による信頼失墜のリスクを大幅に軽減できます。
その結果、企業の信用維持や法的リスクの回避に繋がり、安心して事業を推進できる環境を整備できます。
(※)GDPR=General Data Protection Regulation(EU一般データ保護規則)
EU圏内の個人情報を保護するための法規制で、日本企業もEU関連の事業を行う場合には対応が求められます。
03. データマネジメントを成功させるための実践ステップとポイント
データマネジメントを成功させるためには、計画的かつ継続的な取り組みが不可欠です。
ここでは、具体的な実践ステップと、それぞれのポイントを解説します。
03-1. 目的とゴールの明確化
まず、「何のためにデータマネジメントを行うのか」という目的を明確にすることが最も重要です。
単にデータを管理するだけでなく、売上向上やコスト削減、顧客満足度向上など、経営戦略に紐づいた具体的な目標(KGI・KPI)を設定することで、取り組みの方向性が定まります。
目的が明確になることで、組織全体の方向性が定まり、関係者の一体感や取り組みの効果測定が可能になります。
03-2. 現状把握と課題特定
次に、社内にどのようなデータが、どこに、どのような状態で存在しているのかの現状を調査する「アセスメント」のプロセスを行います。このアセスメントは、そうしたデータのサイロ化、重複、品質のばらつきといった「見えない問題」を可視化するプロセスです。具体的には、主要なデータ資産をリストアップし、そのデータの所有者、利用者、品質レベルを棚卸しします。
部署ごとに異なるシステムでデータが管理されていないか、重複や不整合、欠損といった課題を具体的に洗い出すことが重要です。
現状を正確に把握することで、後工程の設計や効果的な改善策の立案につながります。
03-3. 体制構築とルールの整備
データマネジメントを組織全体で推進するためには、体制構築とルールの整備が不可欠です。
具体的には、CDO(Chief Data Officer:最高データ責任者)を設置し、データ戦略の立案や管理体制の統括を担わせるほか、データ管理委員会の設立など、明確なデータガバナンス体制を構築します。独立行政法人情報処理推進機構(IPA)の調査でも、DXで成果を上げている企業は、CDOやITに知見のある役員の存在比率が高いことが示されています。
参照:「DX白書2021」(独立行政法人情報処理推進機構(IPA))
https://www.ipa.go.jp/publish/wp-dx/qv6pgp0000000txx-att/000093706.pdf(2025年8月18日に利用)
また、データの所有者・責任者、利用ルール、命名規則、品質基準をドキュメント化することも重要です。
さらに、全社員を対象にデータリテラシー向上のための教育・研修を行い、適切なデータ活用ができる人材を育成することで、組織全体の意識を高め、データマネジメントが文化として根付いていきます。
03-4. スモールスタートでPDCAを回す
大規模で複雑なデータマネジメントを、最初から全社一斉に完璧な形で導入しようとすると、計画が肥大化し、頓挫するリスクが高まります。データマネジメントは、いきなり全社導入を目指すのではなく、特定部門や小規模なプロジェクトからスモールスタートで始めることが効果的です。
これによりリスクを抑えつつ、スピーディに具体的な成果を上げられます。
施策の効果測定と改善を繰り返すPDCAサイクル(Plan-Do-Check-Action)を継続的に回すことで、ノウハウを蓄積しながら段階的に適用範囲を拡大していくことが効果的です。
03-5. 成功ポイント:経営層のコミットメントと全社的なデータ文化の醸成
データマネジメントは、IT部門や一部の部署だけの問題ではありません。経営層の強いコミットメントと、全社的な取り組みが不可欠です。
情報システムに関する多くの研究で「トップマネジメントの支援」が最も重要な成功要因の一つとして挙げられています。IPAの調査でも、DXの成果が出ている企業は、そうでない企業に比べてIT分野に見識がある役員の割合が19.1%高いという結果が出ています。
参照:「DX動向2024」(独立行政法人情報処理推進機構(IPA))
https://www.ipa.go.jp/digital/chousa/dx-trend/eid2eo0000002cs5-att/dx-trend-2024.pdf(2025年8月18日に利用)
経営層がデータ活用の重要性を理解し、積極的に推進することで、組織全体に「データに基づく意思決定が当たり前」という文化が根付きます。
データを共通言語とし、全社員が活用できる環境を整えることが、継続的な成果と成功の鍵となります。
04. 【課題別】データマネジメントのよくある悩みと解決策
データマネジメントに取り組む上で、多くの企業が共通の悩みを抱えています。ここでは、理論から実践へと移る際に現れる5つの典型的な悩み、「データのサイロ化」「品質問題」「人材不足」「組織文化」「セキュリティ不安」を取り上げ、その解決策について解説します。
04-1. データが点在し、必要なデータが見つからない(データサイロ化)
各部署やシステムにデータが分散し、必要なデータにたどり着けない「データサイロ化」はよくある課題です。この状態では、顧客の全体像を把握できず、レポート作成のたびに各部署から手作業でデータを集めるなど、膨大な非効率が発生します。
解決策:
データ統合プラットフォームの導入や、社内のデータ資産を一覧化するデータカタログの整備が効果的です。
分散したデータを一元管理し、必要なデータに素早くアクセスできる環境を構築することで、データ探索の時間を大幅に短縮できます。
04-2. データの品質が低く、分析結果が信頼できない(データ品質問題)
「ゴミを入れれば、ゴミしか出てこない(Garbage In, Garbage Out)」という言葉の通り、データの重複・不整合・欠損などデータの品質問題は分析結果の信頼性を根底から揺るがし、誤った判断につながるリスクがあります。
解決策:
不正確なデータを修正・除去する「データクレンジング」や、記録形式を統一する「標準化ルール」の策定と運用、データ入力時のバリデーション(妥当性確認)強化などが有効です。
加えて、定期的なデータ品質の監査・評価を実施し、継続的に改善を図る体制を整備することが重要です。
04-3. データを活用できる人材がいない、育たない(人材不足・スキルギャップ)
データを蓄積していても、それを活用できる人材がいなければ、ビジネスへの貢献にはつながりません。
多くの企業では、データ分析や活用に必要な知識・スキルを持つ人材が不足しているほか、社内での教育体制が整っていないことが課題となっています。
解決策:
段階的な社内研修やeラーニングの導入を通じて、社員のデータリテラシーや分析スキルの底上げを図ることが有効です。
また、すぐに高度な対応が必要な場合は、外部のデータ分析専門家を活用した支援も効果的です。
必要に応じて、プロフェッショナル人材を一時的に常駐させるといった施策も検討できます。
04-4. データ活用に対する社内の理解が得られない(組織文化の課題)
「データ活用は一部の専門家の仕事」「現場には関係ない」といった誤解や、データ活用の意義が社内に浸透していないことは、多くの企業で見られる課題です。
こうした状況では、現場の協力が得られず、取り組みが定着しにくくなります。
解決策:
データ活用の成功事例や具体的な成果を社内で積極的に共有し、業務にどう貢献するのかを“自分ごと”として実感できるようにすることが重要です。
あわせて、経営層主導でのメッセージ発信、部署横断型のプロジェクト立ち上げ、データに関する社内イベントの開催などを通じて、組織全体にデータ活用の文化を浸透させていくことが求められます。
04-5. セキュリティやコンプライアンスへの不安
データのセキュリティリスクや法令遵守は多くの企業共通の課題です。
個人情報や機密情報の漏えい防止には、アクセス権限管理やログ記録、匿名化・マスキングなどの対策と関連法規の遵守が欠かせません。
解決策:
データの匿名化やアクセス権限の厳格管理、関連法規の遵守を徹底しましょう。
また、セキュリティ対策ツールの導入や定期的な監査・診断を行い、安全な環境を整備することが重要です。これらの取り組みにより、組織全体で安心してデータを活用できる体制を構築することが求められます。
05. データマネジメントでDXを推進した成功事例
食品流通企業における、データマネジメントの一元化と活用の成功事例をご紹介します。
<導入前の課題>
グループ会社や部署ごとに個別のシステムが存在し、データがサイロ化していました。各システムのデータフォーマットが不統一で、データガバナンスが機能しておらず、データ品質や鮮度に対する信頼性が低いという課題を抱えていました。また、データの確認コストが高く、セキュリティ対策もシステムごとに異なり、データ活用を阻害していました。
<実施したこと>
データマネジメントチームを組成し、全社的なルールを整備する「データレビュー」を実施。新たな分析基盤の構築と並行して、データ品質、メタデータの管理、データガバナンス、セキュリティ要件の整理を行い、全社で統一されたデータ取り扱いを確立。この取り組みにより、各システムから抽出したデータの連携・活用の基盤を構築しました。
<得られた成果>
データマネジメントチームが主導したデータレビューによって、社内のデータ品質が向上し、分析結果の信頼性が高まりました。加えてデータの適切な加工や、セキュリティ部門との連携体制が確立され、データ活用の基盤が整いました。これにより、データマネジメントが組織に定着し、全社的なデータナレッジの拡充とDX推進の加速に繋がりました。
その他弊社の導入事例はこちらで紹介しています→導入事例 | メンバーズデータアドベンチャー
06. データマネジメントに関するよくある質問(FAQ)
Q1. データマネジメントは中小企業でも必要ですか?
A. はい、企業の規模に関わらず、データは重要な経営資源です。中小企業は大企業に比べてブランド力や資金力が劣るため、顧客データや販売データ、業務データを正しく把握し、素早く経営判断に役立てることがとても大切です。
勘や経験だけで経営を続けると、変化の激しい市場で勝ち残るのは難しくなります。データマネジメントは、限られた資源を効率よく使い、効果的な戦略を立てて競争に強くなるための指針となります。
Q2. データマネジメントツールを導入すれば解決しますか?
A. いいえ、ツールはデータの可能性を引き出すための助けに過ぎません。データマネジメントの本質は、ビジネス課題を解決し価値を生み出すことにあります。
ツールはその過程をスムーズにする手段であり、目的の明確化や体制構築、人材育成といった組織的な取り組みが伴わなければ、高価なツールも十分に活用されません。
まずは、ツール導入前にどんな価値を実現したいのかをはっきりさせることが大切です。
Q3. データマネジメントの人材育成はどのように進めるべきですか?
A. 人材育成は単なるスキル習得ではなく、組織全体のデータリテラシー向上が重要です。人材育成には、二つの階層でのアプローチが効果的です。第一に、専門家だけでなく、すべての従業員がデータの基本的な読み書き能力を身につけるための「全社的なデータリテラシー教育」です。これにより、組織全体でデータを共通言語として話せるようになります。
第二に、データスチュワードやデータアナリストといった「専門人材の育成」です。社内研修や資格取得支援といった内部育成と、必要に応じて外部の専門家を活用するハイブリッドなアプローチが、多くの日本企業にとって現実的な選択肢となっています。
Q4. データマネジメントの効果はいつ頃から現れますか?
A. データマネジメントの効果は、まず社員の意識変化として早期に現れます。効果は段階的に現れます。まず比較的早期(3~6ヶ月程度)に現れるのは、特定の業務における効率化の効果です。例えば、月次のレポート作成時間が半減した、といった目に見える変化です。
一方で、売上向上や顧客満足度の改善といった事業全体へのインパクトや、データに基づいた意思決定が当たり前になる文化の醸成には、1年から2年、あるいはそれ以上の継続的な取り組みが必要です。焦らず、小さな成功を積み重ねていくことが重要です。
Q5. DX推進におけるデータマネジメントの失敗例にはどのようなものがありますか?
A. よくある失敗は、「完璧」を目指しすぎて動けなくなることです。理想のデータ基盤や完全なデータ品質を求めて、最初から大きな投資や複雑なシステムを作ろうとすると、途中でプロジェクトが止まってしまうことが多いです。データマネジメントは、まず小さな成功を積み重ねながら、少しずつ改善していく進め方が大切です。
不完全でもまず始めることで、徐々に良くしていくのが成功のコツです。
まとめ
データマネジメントは、企業が持つデータを「集める」から「捨てる」まで適切に扱い、その価値を最大限に引き出す活動です。信頼性の高いデータは、DX推進に不可欠で、事業成長、顧客体験向上、業務効率化、コスト削減、そして法的リスク軽減に貢献します。
成功には、まず目的を明確にし、現状把握からスモールスタートでPDCAを回すことが重要です。経営層のコミットメントと全社的なデータ文化の醸成も欠かせません。データサイロ化や品質問題、人材不足といった課題は、データ統合やクレンジング、人材育成で解決できます。完璧を目指すより、小さな成功を積み重ねることが成功へのポイントです。
データを資産として正しく活かす力は、今後の企業成長を左右する鍵となります。
変化の激しい時代だからこそ、データマネジメントを一過性の取り組みではなく、継続的な経営戦略の一環として実践していくことが求められます。
弊社データアドベンチャーカンパニーでは、データ基盤の構築から運用・保守まで一気通貫でご支援しております。
情報収集からでも承っておりますので、お気軽にお問い合わせください。
\ データ活用についてのご相談はメンバーズデータアドベンチャーまで /
\ 相談する前に資料を見たいという方はこちら /
▶こちらも要チェック
生成AIや機械学習モデルの進化は目覚ましく、多くの企業がAI活用による業務効率化や新たな価値創出を模索しています。しかし、AIをビジネスに活かすためには、高精度なAIモデルを開発・運用するための「良質なデータ」が不可欠です。本記事では、AIの性能を最大限に引き出すための「データ整備」に焦点を当て、その重要性から具体的な手順まで、AI活用を成功に導くためのポイントを解説します。
▶目次

01.AI・生成AIの性能を決めるデータ整備とは?
01-1. AI活用に向けたデータ整備とは
AIの活用がビジネスにおいて不可欠な要素となりつつある今、多くの企業が直面するのが「AIレディなデータ」をどう準備するかという課題です。
この課題を解決する鍵となるのが、AIのためのデータ整備です。
AI活用におけるデータ整備は、AIが学習・推論するために最適な状態にデータを準備することを意味します。
AIモデルの性能は、学習に用いるデータの質に大きく依存するため、データの正確性、完全性、一貫性を高めることが不可欠です。
例えば、社内外に散在する膨大なデータの中から必要な情報を抽出し、欠損値の補完や表記の統一を行い、さらには画像や音声データに適切なラベル付け(アノテーション)を施すなど、AIが正確に学習・判断できるようにデータを加工します。
このように、AI活用に向けたデータ整備は、単なるデータの管理を超え、AIモデルの性能を決定づける重要なプロセスと言えます。
01-2. 既存のデータ管理・分析との違い
AIのためのデータ整備は、一般的なデータ管理や分析と混同されがちですが、両者には明確な違いがあります。
従来のデータ管理は、基幹システムやデータベースにデータを保管し、必要な時に取り出せるようにすることが主目的でした。データの正確性や一貫性は重視されるものの、あくまで人間が利用することを前提としています。
一方、AIのためのデータ整備は、AIモデルが効率的に学習できるよう、より専門的で緻密な作業が求められます。
特に、AI活用においては個人情報や機密情報を扱うケースも多く、データの収集から整備、学習に至るまで、セキュアな環境の構築と厳格な管理が不可欠です。
それに加えて、テキスト、画像、音声といった非構造化データに対するアノテーション(データに意味付けやラベル付けを行う作業)は、従来のデータ管理にはない、AI特有の要件です。AIは与えられたデータからパターンを認識するため、このラベル付けの品質がAIの認識精度に直結します。
また、AIモデルは特定のデータ形式を要求する場合が多く、多様なフォーマットへの対応や、モデルに合わせたデータの前処理も重要な作業となります。
| 観点 | 従来のデータ管理・分析 | AIのためのデータ整備 |
|---|---|---|
| 目的 | 人間による業務利用、意思決定支援 | AIモデルの学習、予測精度の向上 |
| 対象データ | 構造化データ(数値、テキスト)が中心 | 構造化データに加え、画像、音声などの非構造化データも対象 |
| 主な作業 | データの保管、バックアップ、整理 | データのクレンジング、表記ゆれ統一、欠損値補完、アノテーション |
| 求められる品質 | 人間が理解できる正確性、一貫性 | AIがパターンを認識できる、偏りのない網羅性、一貫性 |
02.なぜAIにはデータ整備が必要なのか?背景と最新動向
02-1. DX推進と「2025年の崖」
DX(デジタルトランスフォーメーション)の推進が叫ばれる中で、多くの企業が直面しているのが経済産業省が警鐘を鳴らす「2025年の崖」問題です。これは、老朽化・複雑化した既存システムが、企業の競争力低下を招くリスクを指す経済産業省のレポートで提起された課題です。このままでは、DXを阻害し、市場での優位性を失う恐れがあるため、早急な対応が求められています。
この課題を克服し、企業が持続的に成長していくためには、DXを加速させるAIの活用が不可欠です。AIは、データに基づいた意思決定を支援し、新たなビジネス価値を創出する強力なツールとなり得ます。しかし、AIを効果的に導入・活用するには、その土台となるデータの準備が何よりも重要です。質の低いデータや、整理されていないデータでは、AIは本来のパフォーマンスを発揮できません。老朽化した既存システムにはデータが散在し、AIが活用できる状態ではありません。
そのため、AI活用の第一歩として、AIレディなデータを準備するためのデータ整備が、「2025年の崖」を乗り越え、DXを成功させるための重要な基盤となります。
参照:「デジタルガバナンス・コード2.0」(経済産業省)
https://www.meti.go.jp/policy/it_policy/investment/dgc/dgc2.pdf(2025年8月18日に利用)
02-2. ビジネス競争力向上のため
DX推進と「2025年の崖」を背景に、AIのためのデータ整備が求められるもう一つの重要な理由は、ビジネス競争力の向上に直結するからです。
今日の市場では、迅速かつ正確な意思決定が企業の明暗を分けます。高品質なデータに基づいたAI活用は、市場トレンドの予測、顧客行動の分析、業務プロセスの最適化などを可能にし、経営層の意思決定を強力にサポートします。これにより、単なる勘や経験に頼るのではなく、データドリブンな経営が実現し、新たなビジネス価値の創出や、顧客体験の向上に繋がるのです。
また、競合他社に先んじてAIを導入することは、市場での優位性を築く上で決定的な要因となります。しかし、AIを導入する際、単にツールを導入するだけでは不十分です。AIの性能を最大限に引き出すためのデータ整備こそが、他社との差別化を図る上で不可欠な要素となります。高品質なデータは、より精度の高いAIモデルを生み出し、企業の競争力を一層高める土台となります。
02-3. プライバシー・セキュリティ要件の遵守
AI活用においてデータ整備が不可欠な理由として、プライバシー・セキュリティ要件の遵守も挙げられます。
AIモデルの学習には膨大なデータが必要となりますが、その中には個人情報や機密情報が含まれるケースが少なくありません。個人情報保護法をはじめとする各種法令や、企業のコンプライアンス要件を遵守するためには、データの取り扱いに細心の注意を払う必要があります。そのため、データ整備のプロセスでは、データの収集段階から、匿名化や仮名化といったプライバシー保護の措置を講じること、そしてデータのアクセス権限を厳密に管理することが不可欠となります。
AIのためのデータ整備は、単にAIの性能を高めるためだけでなく、企業が社会的な信用を維持し、倫理的なAI活用を推進するための重要な土台でもあるのです。安全で公正なAIの活用を実現するためにも、適切なデータ整備と厳格なセキュリティ対策は欠かせません。
03.AIレディなデータ整備、具体的な手順と押さえるべきポイント
ここからは、AIレディなデータ整備を具体的に進めるための手順と、それぞれの段階で押さえるべきポイントを解説します。漠然としたイメージを具体的なアクションに落とし込むことで、より効率的かつ確実にプロジェクトを成功に導くことができます。
03-1. 目的と対象データの明確化
データ整備の第一歩は、
「何のためにAIを活用するのか」という目的を明確に定義し、それに必要なデータは何かを特定することです。この工程はプロジェクト全体の方向性を決定づける最も重要な段階といえます。
例えば、「顧客からの問い合わせ対応を自動化したい」という目的であれば、問い合わせ履歴のテキストデータが主な対象となります。一方、「製造ラインの不良品を検知したい」という目的であれば、製品の画像データが中心となります。目的が曖昧なままデータ整備を始めると、不要なデータの収集に時間やコストを費やしたり、最終的にAIを導入しても期待した成果が得られなかったりするリスクがあります。AI活用の目的を具体的に設定し、それに応じて必要なデータの種類、量、品質要件を事前に定義することが、データ整備を成功させるための第一歩となります。
03-2. 現状データの収集と品質評価
目的と対象データが明確になったら、次に現状データの収集と品質評価を行います。
企業内には、顧客データベース、営業報告書、ウェブサイトのログ、SNS上のコメントなど、様々なデータが散在しています。これらの社内外に存在するデータを、一箇所に集めることから始めます。データが集まったら、次にその品質を評価します。
この評価は、AIモデルの性能を左右する非常に重要なプロセスです。データの品質は、「正確性」「完全性」「一貫性」といった観点からチェックします。
- ・正確性:データに誤りがないか
- ・完全性:欠損している情報はないか
- ・一貫性:表記ゆれや重複がないか
AIの世界には「Garbage In, Garbage Out (ゴミを入れればゴミしか出てこない)」という原則があり、低品質なデータからは精度の低いAIモデルしか生まれません。そのため、データの誤りや欠損を事前に把握する品質評価プロセスが極めて重要です。
03-3. データのクレンジングと前処理
データの収集と品質評価が終わったら、AIがデータを正しく解釈できるようデータのクレンジングと前処理を行います。
この段階では、主に以下のような作業を行います。
- ・欠損値の補完:歯抜けになっているデータ(欠損値)を、平均値や中央値、または他のデータから推測して埋めます。
- ・重複データの排除:同じ内容のデータが複数存在する場合、一つにまとめます。
- ・表記ゆれの統一:「株式会社」と「(株)」、「東京都」と「東京」など、同じ意味なのに表記が異なるデータを統一します。
- ・外れ値の処理:他のデータからかけ離れた極端な値(外れ値)を特定し、削除するか、適切に処理します。
これらの作業を通じて、不正確なデータやノイズを取り除き、データの信頼性を高めます。また、AIモデルが処理しやすい形にデータを変換する前処理も重要です。例えば、テキストデータを数値データに変換したり、画像のサイズを統一したりすることで、AIレディなデータへと変換していきます。この工程を丁寧に行うことが、AIモデルの学習精度を大きく左右します。
03-4. データの構造化とアノテーション
クレンジングと前処理を終えたら、次はデータの構造化とアノテーションです。アノテーションとは、AIモデルがデータをより効率的に学習できるように、データの形を整え、意味を付与する作業です。テキスト、画像、音声といった非構造化データは、そのままではAIがパターンを認識するのが困難です。そのため、AIが理解しやすい構造化データに変換する作業が必要になります。
この作業をアノテーションと呼び、主に以下のような作業が含まれます。
- ・テキストデータ:特定のキーワードや感情をタグ付けする
- ・画像データ:物体の位置を枠で囲んだり、何が写っているかラベル付けする
- ・音声データ:音声の区間に文字起こしを行ったり、話者の識別情報を付与する
アノテーションは、AIの学習精度に直結する重要な工程です。
例えば、画像認識AIの場合、画像の中の物体が何であるかを正確にラベル付けすることで、AIは「これは猫」「これは自動車」といった判断を学習します。アノテーションの品質が低いと、AIは間違った学習をしてしまい、期待通りの性能を発揮できません。そのため、この作業の質と量が、AIモデルの認識精度を決定づけると言っても過言ではありません。
03-5. データガバナンスと継続運用
データ整備は一度行えば終わりではありません。AIを継続的に活用していくためには、データガバナンスと継続運用の体制を確立することが不可欠です。
データは常に変化し、AIモデルも進化するため、データ整備は単発のプロジェクトではなく、PDCAサイクルによる継続的な改善が必要です。
- ・データガバナンスの構築:誰がデータの所有者(データオーナー)であるかを明確にし、データの管理ルールや品質基準を定めます。これにより、データの正確性と一貫性を組織全体で維持することができます。
- ・更新・管理プロセスの整備:新しいデータが継続的に発生するため、定期的にデータを更新し、品質をチェックするプロセスを構築します。これにより、AIモデルは常に最新のデータで学習・推論することが可能になります。
- ・PDCAサイクルの実施:AIモデルのパフォーマンスを定期的に評価し、データに新たな課題が見つかれば、再び収集・整備プロセスに戻り、改善を繰り返します。
このように、データガバナンスと継続的な運用体制を整えることで、AIモデルの性能を長期にわたって維持・向上させ、ビジネス価値を最大化させることができます。
04.AIレディなデータ整備がもたらすビジネスメリットと活用例
AIレディなデータは、単にAIを動かすための燃料に留まりません。それは、業務のあり方を根底から変え、新たなビジネス価値を創造し、企業の意思決定そのものを進化させる、強力なエンジンとなります。本章では、データ整備がもたらす具体的なビジネスメリットを、活用例とともにご紹介します。
04-1. 新たな価値創出と業務効率化
AIレディなデータ整備がもたらす最大のメリットは、これまで見過ごされてきたデータから新たな価値を創出し、業務を劇的に効率化できる点にあります。
多くの企業では、日々膨大なデータが生成されていますが、そのほとんどが十分に活用されていません。データ整備によってこれらのデータがAIにとって理解可能な状態になると、AIはこれまで人間が見つけられなかったパターンや関連性を発見できるようになります。このAIの知見は、新たなサービスの開発や既存事業のイノベーションに繋がり、企業の競争優位性を高める原動力となります。
具体的な活用例としては、以下のようなものが挙げられます。
- ・社内情報の活用と業務効率化:
社内に散在するドキュメント(マニュアル、規定、過去の議事録など)をデータ整備することで、生成AIを活用した社内向けチャットボットを構築できます。これにより、社員は知りたい情報を探し回る必要がなくなり、業務に関する質問に対して即座に回答を得られるようになります。結果として、情報検索にかかっていた工数が大幅に削減され、生産性向上に繋がります。 - ・パーソナライズされたマーケティング:
顧客の購買履歴やウェブサイトの閲覧データを整備・分析することで、AIが個々の顧客に最適な商品をレコメンドしたり、パーソナライズされた広告を配信したりできるようになります。これにより、顧客エンゲージメントの向上と売上増加が見込めます。 - ・需要予測の高度化:
過去の販売データ、天候情報、経済動向などを整備し、AIに学習させることで、より精度の高い需要予測が可能になります。これにより、在庫管理が最適化され、欠品や過剰在庫のリスクを低減できます。
04-2. 意思決定の迅速化とデータドリブン経営促進
AIのためのデータ整備は、単なる業務効率化に留まらず、企業の意思決定を迅速化し、データドリブンな経営を促進するという、より本質的なメリットをもたらします。
従来、経営判断は個人の経験や勘に頼ることが多く、不確実性や判断の遅れが課題でした。しかし、適切に整備されたデータに基づきAIが分析を行うことで、市場の動向、顧客のニーズ、競合の動きなどを客観的かつリアルタイムに把握できるようになります。これにより、経営層はより迅速かつ正確な根拠に基づいた判断を下すことが可能になります。さらに、データ整備を通じて、データの収集、分析、活用が組織全体に浸透することで、データドリブンな企業文化が醸成されます。社員一人ひとりがデータに基づき自律的に考え、行動するようになるため、組織全体のパフォーマンスが向上し、企業の成長を力強く後押しします。
データ整備は、AI活用を成功させるための基盤であると同時に、企業文化そのものを変革する重要なプロセスと言えます。
05.AI活用に向けたデータ整備 成功事例
05-1. 社員の業務工数削減へ貢献する生成AIの構築
本章は弊社メディア記事「なぜ今、DXは“内製化”が鍵なのか?ベンダーロックインを脱して競争優位を築く方法」より引用したものです。
<背景と課題>
弊社では、社内の人材情報とマーケティング情報が複数のスプレッドシートに散在しており、統一されたデータ管理が行えないという課題を抱えていました。部署ごとに管理が分かれ、情報の整合性を取るのに多大な時間がかかっていたほか、現場からは「全体を俯瞰したい」「更新のたびに連携ミスが起きる」といった声も上がっていました。
<プロジェクトの特徴>
このプロジェクトは、弊社サービス開発室のメンバーのみで構成され、完全に内製で進行された点が最大の特長です。さらに、特定の外部可視化サービスや高額なSaaSに依存することなく、汎用性の高いGoogleCloudと無償・社内リソース中心の技術スタックを用いて構築されました。
<取り組み内容>
以下の構成に基づき、Googleスプレッドシート → GoogleCloud → Looker Studioという一連の流れを自動化し、日々の業務で使えるダッシュボードとして運用可能にしました。
- データ収集:Google Apps Scriptによりスプレッドシートの内容を定期収集し、Cloud Storageにアップロード
- データ蓄積:Cloud StorageからBigQueryへデータ転送(Data Transfer Service)
- データ加工・集計:Cloud Functionsを利用し、業務用途に合わせた整形・マート化を実施
- 可視化:Looker StudioでグラフやKPIの可視化ダッシュボードを作成
- 保守と拡張性:Cloud StorageとBigQueryによるバックアップとバージョン管理体制も内製で整備
<成果と効果>
- 完全内製によるスキル蓄積と属人性の排除:全メンバーが設計から運用まで関わったことで、属人性のないドキュメントとナレッジが社内に蓄積されました。
- 意思決定スピードの向上:リアルタイムで人材情報やマーケティング状況を確認できる環境を構築。
- 保守性と汎用性:ツール依存がなく、社内の他業務や他部署にも展開しやすい構成により、高い再利用性を実現。
- コスト削減:外注コストゼロ、SaaS利用費不要で年間30%以上の費用削減につながりました。
<今後の展望>
この仕組みは、現在別部署や他プロジェクトへの横展開が進められており、「社内DXの共通基盤」としての可能性を広げています。今後は、生成AIの活用やより高度な分析機能の内製追加など、さらなる進化を視野に入れています。
![]()
✔️採用にコストをかけず実現するプロの伴走支援
✔️データ整備から内製化までの一貫サポート
サービスの詳細、支援内容、導入事例は下記ページで公開しています。
▶︎サービス内容:データ領域 プロフェッショナル常駐サービス
▶︎導入事例:導入事例 | メンバーズデータアドベンチャー
\ データ活用についてのご相談はメンバーズデータアドベンチャーまで /
06.AIのためのデータ整備に関するよくある質問(FAQ)
Q1. AIのためのデータ整備には、どのくらいの期間とコストがかかりますか?
A. データの量、質、複雑さ、整備の範囲によって大きく異なりますが、小規模なプロジェクトであれば数週間〜数ヶ月、大規模であれば半年〜数年かかることもあります。コストはそれに比例し、専門ツールや外部委託費用も考慮すると数百万〜数千万かかることもあるでしょう。
Q2. 自社に専門家がいなくてもAI活用に向けたデータ整備は可能ですか?
A. 部分的には可能ですが、高品質なデータ整備を実現し、AIプロジェクトを成功に導くためには専門家の知見が不可欠です。専門家がいない場合、外部の支援サービスを活用することが有効な選択肢となるでしょう。
データ整備には統計学の知識やプログラミングスキルなど、専門的なスキルセットが求められます。近年はデータ整備のアウトソーシングサービスも充実しており、専門企業に委託することもできます。
Q3. データ整備の際に特に注意すべき点は何ですか?
A. データ整備を進める上では、技術的な課題だけでなく、プロジェクトの進め方や管理体制に関する点にも注意を払う必要があります。特に以下の4点は、多くのプロジェクトで見られる失敗の要因です。
- ・目的の不明確さ:AI活用の目的が曖昧なまま始めると、時間とコストを浪費します。
- ・データ品質が低い:品質チェックを怠ると、後の工程で大規模な手戻りが発生しかねません。
- ・セキュリティ・プライバシーへの配慮不足:情報漏洩などの重大なインシデントを引き起こすリスクがあります。
- ・継続的な運用体制の欠如:一度きりの作業と捉えると、AIモデルの性能は劣化します。
Q4. AIのためのデータ整備は一度行えば終わりですか?
A. いいえ、データ整備は一度行えば終わりという性質のものではなく、継続的な運用と改善が不可欠なプロセスです。ビジネス環境は常に変化するため、AIモデルも定期的に最新のデータで再学習させなければ、予測精度は低下します。
この現象は「モデルの劣化(ドリフト)」と呼ばれています。AIの価値を長期的に維持・向上させるには、データ整備を事業に組み込まれた継続的な活動として位置づけ、運用体制を構築することが極めて重要です。
まとめ
本記事では、「AIのためのデータ整備」をテーマに、その重要性から具体的な手順、得られるメリットまでを解説しました。
- ・データ整備とは:AIが学習しやすいように、データを整理し、品質を高めるプロセスです。一般的なデータ管理とは異なり、アノテーションやセキュリティ対策など、AI活用のための専門的な作業が含まれます。
- ・データ整備が必要な理由:DX推進、ビジネス競争力向上、プライバシー・セキュリティ要件の遵守など、AIを効果的に活用し、企業価値を高める上で不可欠な要素です。
- ・データ整備の手順:「目的設定」「データの収集と評価」「クレンジングと前処理」「構造化とアノテーション」「継続的な運用」という5つのステップが重要となります。
- ・データ整備がもたらすメリット:業務効率化や新たな価値創出、そして迅速な意思決定を可能にし、データドリブンな企業経営を促進します。
AI活用は、単に最新技術を導入することではありません。その基盤となるデータをいかに整備し、活用できるかが成功の鍵を握ります。データ整備は手間とコストがかかる作業ですが、その先に待つのは、ビジネスの変革と持続的な成長です。ぜひ、本記事をAI活用の第一歩としてご活用ください。
\ データ活用についてのご相談はメンバーズデータアドベンチャーまで /
\ 相談する前に資料を見たいという方はこちら /